Since the year-end mini-update, progress has continued on cppfront. (If you don’t know what this personal project is, please see the CppCon 2022 talk on YouTube.)
This update covers Acknowledgments, and highlights of what’s new in the compiler and language since last time, including:
- simple, mathematically safe, and efficient chained comparisons
- named
break and continue
- “simple and safe” starts with . . .
main
- user-defined
type, including unifying all special member functions as operator=
- type/namespace/function/object aliases
- header
reflect.h with the start of the reflection API and the first 10 working compile-time metafunctions from P0707
- unifying functions and blocks, including removing
: and = from the for loop syntax
Acknowledgments: 267 issues, 128 pull requests, and new collaborators
I want to say a big “thank you” again to everyone who has participated in the cppfront repo. Since the last update, I’ve merged PRs from Jo Bates, Gabriel Gerlero, jarzec, Greg Marr, Pierre Renaux, Filip Sajdak and Nick Treleaven. Thanks also to many great issues opened by (as alphabetically as I can): Abhinav00, Robert Adam, Adam, Aaron Albers, Alex, Graham Asher, Peter Barnett, Sean Baxter, Jan Bielak, Simon Buchan, Michael Clausen, ct-clmsn, Joshua Dahl, Denis, Matthew Deweese, dmicsa, dobkeratops, Deven Dranaga, Konstantin F, Igor Ferreira, Stefano Fiorentino, fknauf, Robert Fry, Artie Fuffkin, Gabriel Gerlero, Matt Godbolt, William Gooch, ILoveGoulash, Víctor M. González, Terence J. Grant, GrigorenkoPV, HALL9kv0, Morten Hattesen, Neil Henderson, Michael Hermier, h-vetinari, Stefan Isak, Tim Keitt, Vanya Khodor, Hugo Lindström, Ferenc Nandor Janky, jarzec, jgarvin, Dominik Kaszewski, kelbon, Marek Knápek, Emilia Kond, Vladimir Kraus, Ahmed Al Lakani, Junyoung Lee, Greg Marr, megajocke, Thomas Neumann, Niel, Jim Northrup, Daniel Oberhoff, Jussi Pakkanen, PaTiToMaSteR, Johel Ernesto Guerrero Peña, Bastien Penavayre, Daniel Pfeifer, Piotr, Davide Pomi, Andrei Rabusov, rconde01, realgdman, Alex Reinking, Pierre Renaux, Alexey Rochev, RPeschke, Sadeq, Filip Sajdak, satu, Wolf Seifert, Tor Shepherd, Luke Shore, Zenja Solaja, Francis Grizzly Smit, Sören Sprößig, Benjamin Summerton, Hypatia of Sva, SwitchBlade, Ramy Tarchichy, tkielan, Marzo Sette Torres Junior, Nick Treleaven, Jan Tusil, userxfce, Ezekiel Warren, Kayla Washburn, Tyler Weaver, Will Wray, and thanks also to many others who participated on PR reviews and comment threads.
These contributors represent people from high school and undergrad students to full professors, from commercial developers to conference speakers, and from every continent except Antarctica. Thank you!
Next, here are some highlights of things added to the cppfront compiler in the four months since the previous update linked at top.
Simple, mathematically safe, and efficient chained comparisons (commit)
P0515 “Consistent comparison” (aka “spaceship”) was the first feature derived from this Cpp2 work to be adopted into the ISO Standard for C++, in C++20. That means cppfront didn’t have to do much to implement operator<=> and its generative semantics, because C++20 compilers already do so, which is great. Thank you again to everyone who helped land this Cpp2 feature in the ISO C++ Standard.
However, one part of P0515 isn’t yet merged into ISO C++: chained comparisons from P0515 section 3.3, such as min <= index < max. See also Barry Revzin‘s great followup ISO C++ proposal paper P0893 “Chaining comparisons.” The cppfront compiler now implements this as described in those ISO proposal papers, and:
- Supports all mathematically meaningful and safe chains like
min <= index < max, with efficient single evaluation of index. (In today’s C++, this kind of comparison silently compiles but is a bug. See P0893 for examples from real-world use.)
- Rejects nonsense chains like
a >= b < c and d != e != f at compile time. (In today’s C++, and in other languages like Python, they silently compile but are necessarily a bug because they are conceptually meaningless.)
I think this is a great example to demonstrate that “simple,” “safe,” and “fast” are often not in tension, and how it’s often possible to get all three at the same time without compromises.
Named break and continue (commit)
This feature further expands the Cpp2 “name :” way of introducing all names, to also support introducing loop names. Examples like the following now work… see test file pure2-break-continue.cpp2 for more examples.
outer: while i<M next i++ { // loop named "outer"
// ...
inner: while j<N next j++ { // loop named "inner"
// ...
if something() {
continue inner; // continue the inner loop
}
// ...
if something_else() {
break outer; // break the outer loop
}
// ...
}
// ...
}
“Simple and safe” starts with . . . main
main can now be defined to return nothing, and/or as main: (args) to have a single argument of type std::vector<std::string_view>.
For example, here is a complete compilable and runnable program (in -pure-cpp2 mode, no #include is needed to use the C++ standard library)…
main: (args) =
std::cout << "This program's name is (args[0])$";
Yes, this really is 100% C++ under the covers as you can see on Godbolt Compiler Explorer… “just nicer”:
- The entire C++ standard library is available directly with zero thunking, zero wrapping, and zero need to
#include or import because in pure Cpp2 the entire ISO C++ standard library is just always automatically there. (Yes, if you don’t like cout, you can use the hot-off-the-press C++23 std::print too the moment that your C++ implementation supports it.)
- Convenient defaults, such as no need to write
-> int, and no need to write braces around a single-statement function body.
- Convenient semantics and services, such as
$ string interpolation. Again, all fully compatible with today’s C++ (e.g., string interpolation uses std::to_string where available).
- Type and memory safety by default even in this example: Not only is
args defaulting to the existing best practices of C++ standard safety with ISO C++ vector and string_view, but the args[0] call is automatically bounds-checked by default too.
type: User-defined types
User-defined types are written using the same name : kind = value syntax as everything in Cpp2:
mytype: type =
{
// data members are private by default
x: std::string;
// functions are public by default
protected f: (this) = { do_something_with(x); }
// ...
}
Here are some highlights…
First, types are order-independent. Cpp2 still has no forward declarations, and you can just write types that refer to each other. For example, see the test case pure2-types-order-independence-and-nesting.cpp2.
The this parameter is explicit, and has special sauce:
this is a synonym for the current object (not a pointer).this defaults to the current type.this‘s parameter passing style declares what kind of function you’re writing. For example, (in this) (or just (this) since “in” is the default as usual) clearly means a “const” member function because “in” parameters always imply constness; (inout this) means a non-const member function; (move this) expresses and emits a Cpp1 &&-qualified member function; and so on.
For example, here is how to write const member function named print that takes a const string value and prints this object’s data value and the string message (yes, everything in Cpp2 is const by default except for local-scope variables):
mytype: type =
{
data: i32; // some data member (private by default)
print: (this, msg: std::string) = {
std::cout << data << msg;
// "data" is shorthand for "this.data"
}
// ...
}
All Cpp1 special member functions (including construction, assignment, destruction) and conversions are unified as operator=, default to memberwise semantics and safe “explicit” by default, and there’s a special that parameter that makes writing copy/move in particular simpler and safer. On the cppfront wiki, see the Design Note “operator=, this & that” for details. Briefly summarizing here:
- The only special function every type must have is the destructor. If you don’t write it by hand, a public nonvirtual destructor is generated by default.
- If no
operator= functions are written by hand, a public default constructor is generated by default.
- All other
operator= functions are explicitly written, either by hand or by opting into applying a metafunction (see below).
Note: Because generated functions are always opt-in, you can never get a generated function that’s wrong for your type, and so Cpp2 doesn’t need to support “=delete” for the purpose of suppressing unwanted generated functions.
- The most general form of
operator= is operator=: (out this, that) which works as a unified general {copy, move} x { constructor, assignment } operator, and generates all of four of those in the lowered Cpp1 code if you didn’t write a more specific one yourself (see Design Note linked above for details).
- All copy/move/comparison
operator= functions are memberwise by default in Cpp2 ( [corrected:] including memberwise construction and assignment when you write them yourself, in which case they aren’t memberwise by default in today’s Cpp1).
- All conversion
operator= functions are safely “explicit” by default. To opt into an implicit conversion, write the implicit qualifier on the this parameter.
- All functions can have a
that parameter which is just like this (knows it’s the current type, can be passed in all the usual ways, etc.) but refers to some other object of this type rather than the current object. It has some special sauce for simplicity and safety, including that the language ensures that the members of a that object are safely moved from only once.
Virtual functions and base classes are all about “this”:
- Virtual functions are written by specifying exactly one of
virtual, override, or final on the this parameter.
- Base classes are written as members named
this. For example, just as a class could write a data member as data: string = "xyzzy";, which in Cpp2 is pronounced “data is a string with default value ‘xyzzy'”, a base class is written as this: Shape = (default, values);, which is naturally pronounced as “this IS-A Shape with these default values.” There is no separate base class list or separate member initializer list.
- Because base and member subobjects are all declared in the same place (the
type body) and initialized in the same place (an operator= function body), they can be written in any order, including interleaved, and are still guaranteed to be safely initialized in declared order. This means that in Cpp2 you can declare a data member object before a base class object, so that it naturally outlives the base class object, and so you don’t need workarounds like Boost’s base_from_member because all of the motivating examples for that can be written directly in Cpp2. See my comments on cppfront issue #334 for details.
Alias support: Type, namespace, function, and object aliases (commit)
Cpp2 already defines every new entity using the syntax “name : kind = value“.
So how should it declare aliases, which declare not a new entity but a synonym for an existing entity? I considered several alternatives, and decided to try out the identical declaration syntax except changing = (which connotes value setting) to == (which connotes sameness):
// Namespace alias
lit: namespace == ::std::literals;
// Type alias
pmr_vec: <T> type
== std::vector<T, std::pmr::polymorphic_allocator<T>>;
// Function alias
func :== some_original::inconvenient::function_name;
// Object alias
vec :== my_vector; // note: const&, aliases are never mutable
Note again the const default. For now, Cpp2 supports only read-only aliases, not read-write aliases.
Header reflect.h: Initial support for reflection API, and implementing the first 10 working metafunctions from P0707… interface, polymorphic_base, ordered, weakly_ordered, partially_ordered, basic_value, value, weakly_ordered_value, partially_ordered_value, struct
Disclaimer: I have not yet implemented a reflection operator that Cpp2 code can invoke, or written a Cpp2 interpreter to run inside the compiler. But I am doing everything else needed for type metafunctions: cppfront has started a usable reflection metatype API, and has started getting working metafunctions that are compile-time code that uses that metatype API… the only thing missing is that those functions aren’t run through an interpreter (yet).
For example, cppfront now supports code like the following… importantly, “value” and “interface” are not built-in types hardwired into the language as they are in Java and C# and other languages, but rather each is a function that uses the reflection API to apply requirements and defaults to the type (C++ class) being written:
// Point2D is declaratively a value type: it is guaranteed to have
// default/copy/move construction and <=> std::strong_ordering
// comparison (each generated with memberwise semantics
// if the user didn't write their own, because "@value" explicitly
// opts in to ask for these functions), a public destructor, and
// no protected or virtual functions... the word "value" carries
// all that meaning as a convenient and readable opt-in, but
// without hardwiring "value" specially into the language
//
Point2D: @value type = {
x: i32 = 0; // data members (private by default)
y: i32 = 0; // with default values
// ...
}
// Shape is declaratively an abstract base class having only public
// and pure virtual functions (with "public" and "virtual" applied
// by default if the user didn't write an access specifier on a
// function, because "@interface" explicitly opts in to ask for
// these defaults), and a public pure virtual destructor (generated
// by default if not user-written)... the word "interface" carries
// all that meaning as a convenient and readable opt-in, but
// without hardwiring "interface" specially into the language
//
Shape: @interface type = {
draw: (this);
move: (inout this, offset: Point2D);
}
At compile time, cppfront parses the type’s body and then invokes the compile-time metafunction (here value or interface), which enforces requirements and applies defaults and generates functions, such as… well, I can just paste the actual code for interface from reflect.h, it’s pretty readable:
Note: For now I wrote the code in today’s Cpp1 syntax, which works fine as Cpp2 is just a fully compatible alternate syntax for the same true C++… later this year I aim to start self-hosting and writing more of cppfront itself in Cpp2 syntax, including functions like these.
//-----------------------------------------------------------------------
// Some common metafunction helpers (metafunctions are just
// functions, so they can be factored as usual)
//
auto add_virtual_destructor(meta::type_declaration& t)
-> void
{
t.require( t.add_member( "operator=: (virtual move this) = { }"),
"could not add virtual destructor");
}
//-----------------------------------------------------------------------
//
// "... an abstract base class defines an interface ..."
//
// -- Stroustrup (The Design and Evolution of C++, 12.3.1)
//
//-----------------------------------------------------------------------
//
// interface
//
// an abstract base class having only pure virtual functions
//
auto interface(meta::type_declaration& t)
-> void
{
auto has_dtor = false;
for (auto m : t.get_members())
{
m.require( !m.is_object(),
"interfaces may not contain data objects");
if (m.is_function()) {
auto mf = m.as_function();
mf.require( !mf.is_copy_or_move(),
"interfaces may not copy or move; consider a virtual clone() instead");
mf.require( !mf.has_initializer(),
"interface functions must not have a function body; remove the '=' initializer");
mf.require( mf.make_public(),
"interface functions must be public");
mf.make_virtual();
has_dtor |= mf.is_destructor();
}
}
if (!has_dtor) {
add_virtual_destructor(t);
}
}
Note a few things that are demonstrated here:
.require (a convenience to combine a boolean test with the call to .error if the test fails) shows how to implement enforcing custom requirements. For example, an interface should not contain data members. If any requirement fails, the error output is presented as part of the regular compiler output — metafunctions extend the compiler, in a disciplined way..make_virtual shows how to implement applying a default. For example, interface functions are virtual by default even if the user didn’t write (virtual this) explicitly..add_member shows how to generate new members from legal source code strings. In this example, if the user didn’t write a destructor, we write a virtual destructor for them by passing the ordinary code to the .add_member function, which reinvokes the lexer to tokenize the code, the parser to generate a declaration_node parse tree from the code, and then if that succeeds adds the new declaration to this type.- The whole metafunction is invoked by the compiler right after initial parsing is complete (right after we parse the statement-node that is the initializer) and before the type is considered defined. Once the metafunction returns, if it had no errors then the type definition is complete and henceforth immutable as usual. This is how the metafunction gets to participate in deciding the meaning of the code the user wrote, but does not create any ODR confusion — there is only one immutable definition of the type, a type cannot be changed after it is defined, and the metafunction just gets to participate in defining the type just before the definition is cast in stone, that’s all.
- The metafunction is ordinary compile-time code. It just gets invoked by the compiler at compile time in disciplined and bounded ways, and with access to bounded things.
Today in cppfront, metafunctions like value and interface are legitimately doing everything envisioned for them in P0707 except for being run through an interpreter — the metafunctions are using the meta:: API and exercising it so I can learn how that API should expand and become richer, cppfront is spinning up a new lexer and parser when a metafunction asks to do code generation to add a member, and then cppfront is stitching the generated result into the parse tree as if it had been written by the user explicitly… this implementation is doing everything I envisioned for it in P0707 except for being run through an interpreter.
As of this writing, here are the currently implemented metafunctions in reflect.h are as described in P0707 section 3, sometimes with a minor name change… and including links to the function source code…
interface: An abstract class having only pure virtual functions.
- Requires (else diagnoses a compile-time error) that the user did not write a data member, a copy or move operation, or a function with a body.
- Defaults functions to be virtual, if the user didn’t write that explicitly.
- Generates a pure virtual destructor, if the user didn’t write that explicitly.
polymorphic_base (in P0707, originally named base_class): A pure polymorphic base type that has no instance data, is not copyable, and whose destructor is either public and virtual or protected and nonvirtual.
- Requires (else diagnoses a compile-time error) that the user did not write a data member, a copy or move operation, and that the destructor is either public+virtual or protected+nonvirtual.
- Defaults members to be
public, if the user didn’t write that explicitly.
- Generates a public pure virtual destructor, if the user didn’t write that explicitly.
ordered: A totally ordered type with operator<=> that implements std::strong_ordering.
- Requires (else diagnoses a compile-time error) that the user did not write an
operator<=> that returns something other than strong_ordering.
- Generates that
operator<=> if the user didn’t write one explicitly by hand.
Similarly, weakly_ordered and partially_ordered do the same for std::weak_ordering and std::partial_ordering respectively. I chose to call the strongly-ordered one “ordered,” not “strong_ordered,” because I think the one that should be encouraged as the default should get the nice name.
basic_value: A type that is copyable and has value semantics. It must have all-public default construction, copy/move construction/assignment, and destruction, all of which are generated by default if not user-written; and it must not have any protected or virtual functions (including the destructor).
- Requires (else diagnoses a compile-time error) that the user did not write some but not all of the copy/move/ construction/assignment and destruction functions, a non-public destructor, or any protected or virtual function.
- Generates a default constructor and memberwise copy/move construction and assignment functions, if the user didn’t write them explicitly.
value: A basic_value that is totally ordered.
Note: Many of you would call this a “regular” type… but I recognize that there’s a difference of opinion about whether “regular” includes ordering. That’s one reason I’ve avoided the word “regular” here, and this way we can all separately talk about a basic_value (which may not include ordering) or a value (which does include strong total ordering; see next paragraph for weaker orderings) and we can know we’re all talking about the same thing.
Similarly, weakly_ordered_value and partially_ordered_value do the same for weakly_ordered and partially_ordered respectively. I again chose to call the strongly-ordered one “value,” not “strongly_ordered_value,” because I think the one that should be encouraged as the default should get the nice name.
struct (in P0707, originally named plain_struct because struct is a reserved word in Cpp1… but struct isn’t a reserved word in Cpp2): A basic_value where all members are public, there are no virtual functions, and there are no user-written (non-default operator=) constructors, assignment operators, or destructors.
- Requires (else diagnoses a compile-time error) that the user did not write a virtual function or a user-written
operator=.
- Defaults members to be
public, if the user didn’t write that explicitly.
Local statement/block parameters (commit)
I had long intended to support the following unification of functions and blocks, where cppfront already provided all of these except only the third case:
f:(x: int = init) = { ... } // x is a parameter to the function
f:(x: int = init) = statement; // same, { } is implicit
:(x: int = init) = { ... } // x is a parameter to the lambda
:(x: int = init) = statement; // same, { } is implicit
(x: int = init) { ... } // x is a parameter to the block
(x: int = init) statement; // same, { } is implicit
{ ... } // x is a parameter to the block
statement; // same, { } is implicit
(Recall that in Cpp2 : always and only means “declaring a new thing,” and therefore also always has an = immediately or eventually to set the value of that new thing.)
The idea is to treat functions and blocks/statements uniformly, as syntactic and semantic subsets of each other:
- A named function has all the parts: A name, a
: (and therefore =) because we’re declaring a new entity and setting its value, a parameter list, and a block (possibly an implicit block in the convenience syntax for single-statement bodies).
- An unnamed function drops only the name: It’s still a declared new entity so it still has
: (and =), still has a parameter list, still has a block.
- (not implemented until now) A parameterized block drops only the name and
: (and therefore =). A parameterized block is not a separate entity (there’s no : or =), it’s part of its enclosing entity, and therefore it doesn’t need to capture.
- Finally, if you drop also the parameter list, you have an ordinary block.
In this model, the third (just now implemented) option above allows a block parameter list, which does the same work as “let” variables in other languages, but without a “let” keyword. This would subsume all the Cpp1 loop/branch scope variables (and more generally than in Cpp1 today, because you could declare multiple parameters easily which you can’t currently do with the Cpp1 loop/branch scope variables).
So this now works, pasting from test case pure2-statement-scope-parameters.cpp2:
main: (args) =
{
local_int := 42;
// 'in' statement scope variable
// declares read-only access to local_int via i
(i := local_int) for args do (arg) {
std::cout << i << "\n"; // prints 42
}
// 'inout' statement scope variable
// declares read-write access to local_int via i
(inout i := local_int) {
i++;
}
std::cout << local_int << "\n"; // prints 43
}
Note that block parameters enable us to use the same declarative data-flow for local statements and blocks as for functions: Above, we declare a block (a statement, in this case a single loop, is implicitly treated as a block) that is read-only with respect to the local variable, and declare another to be read-write with respect to that variable. Being able to declare data flow is important for writing correct and safe code.
Corollary: Removed : and = from for
Eagle-eyed readers of the above example will notice a change: As a result of unifying functions and blocks, I realized that the for loop syntax should use the third syntax, not the first or second, because the loop body is a parameterized block, not a local function. So changed the for syntax from this
// previous syntax
for items do: (item) = {
x := local + item;
// ...
}
to this, which is the same except that it removes : and =
// current syntax
for items do (item) {
x := local + item;
// ...
}
Note that what follows for ... do is exactly a local block, just the parameter item doesn’t write an initializer because it is implicitly initialized by the for loop with each successive value in the range.
By the way, this is the first breaking change from code that I’ve shown publicly, so cppfront also includes a diagnostic for the old syntax to steer you to the new syntax. Compatibility!
Other features
Also implemented since last time:
- As always, lots of bug fixes and diagnostic improvements.
- Use
_ as wildcard everywhere, and give a helpful diagnostic if the programmer tries to use “auto.”
- Namespaces. Every namespace must have a name, and the anonymous namespace is supported by naming it
_ (the “don’t care” wildcard). For now these are a separate language feature, but I’m still interested in exploring making them just another metafunction.
- Explicit template parameter lists. A type parameter, spelled “: type”, is the default. For examples, see test case
pure2-template-parameter-lists.cpp2
- Add requires-clause support.
- Make
: _ (deduced type) the default for function parameters. In response to a lot of sustained user demand in issues and comments — thanks! For example, add: (x, y) -> _ = x+y; is a valid Cpp2 generic function that means the same as (and compiles to) [[nodiscard]] auto add(auto const& x, auto const& y) -> auto { return x+y; } in Cpp1 syntax.
- Add
alien_memory<T> as a better spelling for T volatile. The main problem with volatile isn’t the semantics — those are deliberately underspecified, and appropriate for talking about “memory that’s outside the C++ program that the compiler can’t assume it knows anything about” which is an important low-level concept. The problems with volatile are that (a) it’s wired throughout the language as a type qualifier which is undesirable and unnecessary, and (b) the current name is confusing and has baggage and so it should be named something that connotes what it’s actually for (and I like “alien” rather than “foreign” because I think “alien” has a better and stronger connotation).
- Reject more implicit narrowing, notably floating point narrowing.
- Reject shadowing of type scope names. For example, in a type that has a member named
data, a member function can’t write a local variable named data.
- Add support for
forward return and generic out parameters.
- Add support for raw string literals with interpolation.
- Add compiler switches for compatibility with popular no-exceptions/no-RTTI modes (
-fno-exceptions and -fno-rtti, as usual), specifying the output file (-o, with the option of -o stdout), and source line/column format for error output (MSVC style or GCC style)
- Add single-word aliases (e.g.,
ulonglong) to replace today’s multi-keyword platform-width C types, with diagnostics support to aid migration. This is in addition to known-width Cpp2 types (e.g., i32) that are already there and should often be preferred.
- Allow unnamed objects (not just unnamed functions, aka lambdas) at expression scope.
- Reclaim many Cpp1 keywords for ordinary use. For example, a type or variable can be named “and” or “struct” in Cpp2, and it’s fully compatible (it’s prefixed with “cpp2_” when lowered to Cpp1, so Cpp1 code still has a way to refer to it, but Cpp2 gets to use the nice names). This isn’t just sugar… without this, I couldn’t write the “struct” metafunction and give it the expected nice name.
- Support
final on a type.
- Add support for
.h2 header files.
What’s next
Well, that’s all so far.
For cppfront, over the summer and fall I plan to:
- implement more metafunctions from my paper P0707, probably starting with
enum and union (a safe union) — not only because they’re next in the paper, but also because I use those features in cppfront today and so I’ll need them working in Cpp2 when it comes time to…
- … start self-hosting cppfront, i.e., start migrating parts of cppfront itself to be written in Cpp2 syntax;
- continue working my list of pending Cpp2 features and implementing them in cppfront; and
- start finding a few private alpha testers to work with, to start writing a bit of code in Cpp2 to alpha-test cppfront and also to alpha-test my (so far unpublished) draft documentation.
For conferences:
- One week from today, I’ll be at C++Now to give a talk about this progress and why full-fidelity compatibility with ISO C++ is essential (and what it means). C++Now is a limited-attendance conference, and it’s nearly sold out but the organizers say there are a few seats left… you can still register for C++Now until Friday.
- In early October I hope to present a major update at CppCon 2023, where registration just opened (yes, you can register now! run, don’t walk!). I hope to see many more of you there at the biggest C++ event, and that only happens once a year — like every year, I’ll be there all week long to not miss a minute.
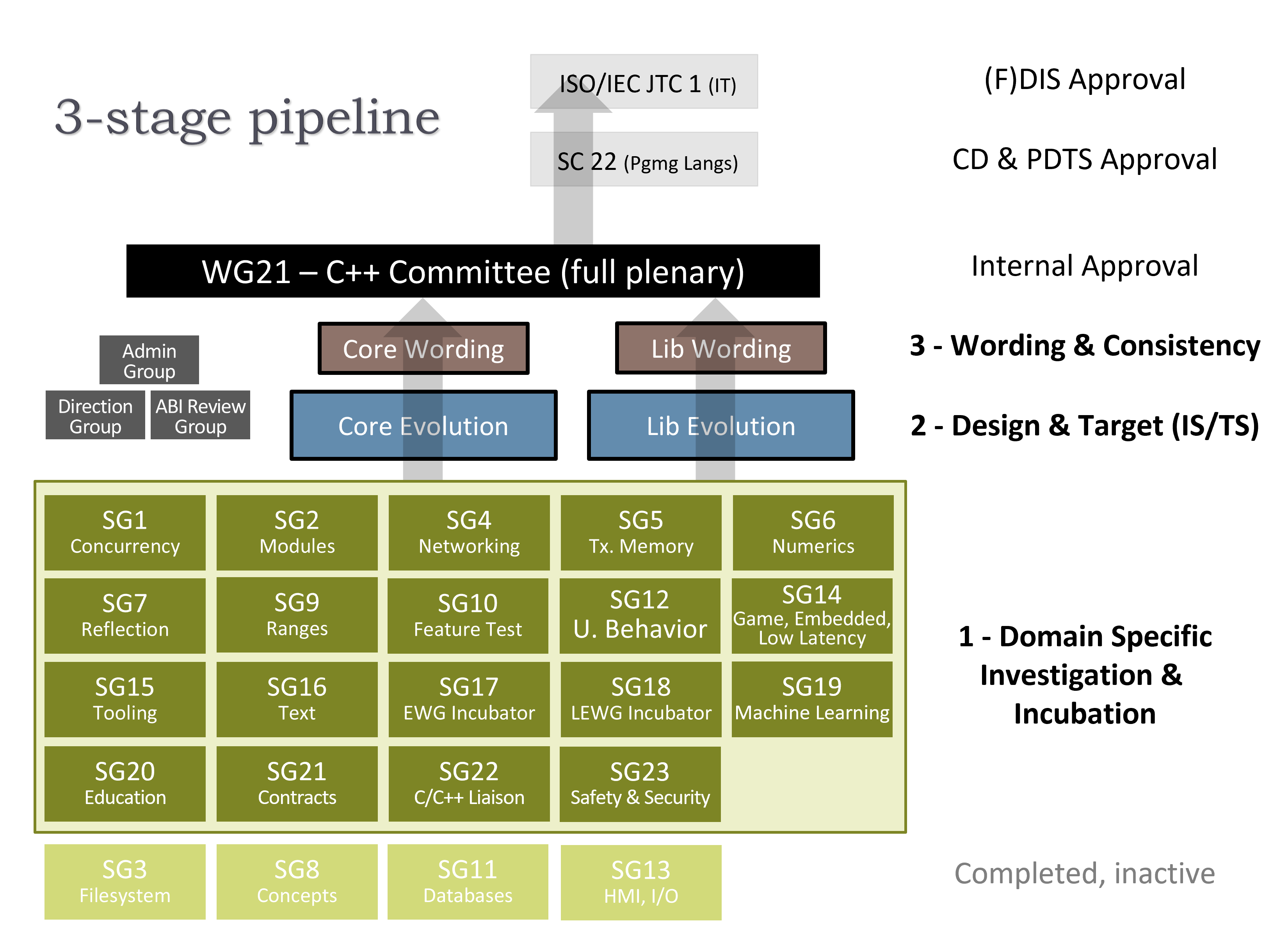




{kind=link}