NOTE: Last year, I posted three new GotWs numbered #103-105. I decided leaving a gap in the numbers wasn’t best after all, so I am renumbering them to #89-91 to continue the sequence. Here is the updated version of what was GotW #103.
There’s a lot to love about standard smart pointers in general, and unique_ptr in particular.
Problem
JG Question
1. When should you use shared_ptr vs. unique_ptr? List as many considerations as you can.
Guru Question
2. Why should you almost always use make_shared to create an object to be owned by shared_ptrs? Explain.
3. Why should you almost always use make_unique to create an object to be initially owned by a unique_ptr? Explain.
4. What’s the deal with auto_ptr?
Solution
1. When should you use shared_ptr vs. unique_ptr?
When in doubt, prefer unique_ptr by default, and you can always later move-convert to shared_ptr if you need it. If you do know from the start you need shared ownership, however, go directly to shared_ptr via make_shared (see #2 below).
There are three major reasons to say “when in doubt, prefer unique_ptr.”
First, use the simplest semantics that are sufficient: Choose the right smart pointer to most directly express your intent, and what you need (now). If you are creating a new object and don’t know that you’ll eventually need shared ownership, use unique_ptr which expresses unique ownership. You can still put it in a container (e.g., vector<unique_ptr<widget>>) and do most other things you want to do with a raw pointer, only safely. If you later need shared ownership, you can always move-convert the unique_ptr to a shared_ptr.
Second, a unique_ptr is more efficient than a shared_ptr. A unique_ptr doesn’t need to maintain reference count information and a control block under the covers, and is designed to be just about as cheap to move and use as a raw pointer. When you don’t ask for more than you need, you don’t incur overheads you won’t use.
Third, starting with unique_ptr is more flexible and keeps your options open. If you start with a unique_ptr, you can always later convert to a shared_ptr via move, or to another custom smart pointer (or even to a raw pointer) via .get() or .release().
Guideline: Prefer to use the standard smart pointers, unique_ptr by default and shared_ptr if sharing is needed. They are the common types that all C++ libraries can understand. Use other smart pointer types only if necessary for interoperability with other libraries, or when necessary for custom behavior you can’t achieve with deleters and allocators on the standard pointers.
2. Why should you almost always use make_shared to create an object to be owned by shared_ptrs? Explain.
Note: If you need to create an object using a custom allocator, which is rare, you can use allocate_shared. Note that even though its name is slightly different, allocate_shared should be viewed as “just the flavor of make_shared that lets you specify an allocator,” so I’m mainly going to talk about them both as make_shared here and not distinguish much between them.
There are two main cases where you can’t use make_shared (or allocate_shared) to create an object that you know will be owned by shared_ptrs: (a) if you need a custom deleter, such as because of using shared_ptrs to manage a non-memory resource or an object allocated in a nonstandard memory area, you can’t use make_shared because it doesn’t support specifying a deleter; and (b) if you are adopting a raw pointer to an object being handed to you from other (usually legacy) code, you would construct a shared_ptr from that raw pointer directly.
Guideline: Use make_shared (or, if you need a custom allocator, allocate_shared) to create an object you know will be owned by shared_ptrs, unless you need a custom deleter or are adopting a raw pointer from elsewhere.
So, why use make_shared (or, if you need a custom allocator, allocate_shared) whenever you can, which is nearly always? There are two main reasons: simplicity, and efficiency.
First, with make_shared the code is simpler. Write for clarity and correctness first.
Second, using make_shared is more efficient. The shared_ptr implementation has to maintain housekeeping information in a control block shared by all shared_ptrs and weak_ptrs referring to a given object. In particular, that housekeeping information has to include not just one but two reference counts:
- A “strong reference” count to track the number of shared_ptrs currently keeping the object alive. The shared object is destroyed (and possibly deallocated) when the last strong reference goes away.
- A “weak reference” count to track the number of weak_ptrs currently observing the object. The shared housekeeping control block is destroyed and deallocated (and the shared object is deallocated if it was not already) when the last weak reference goes away.
If you allocate the object separately via a raw new expression, then pass it to a shared_ptr, the shared_ptr implementation has no alternative but to allocate the control block separately, as shown in Example 2(a) and Figure 2(a).
// Example 2(a): Separate allocation
auto sp1 = shared_ptr<widget>{ new widget{} };
auto sp2 = sp1;
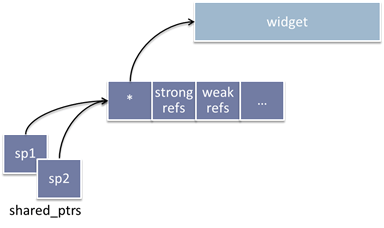
Figure 2(a): Approximate memory layout for Example 2(a).
We’d like to avoid doing two separate allocations here. If you use make_shared to allocate the object and the shared_ptr all in one go, then the implementation can fold them together in a single allocation, as shown in Example 2(b) and Figure 2(b).
// Example 2(b): Single allocation
auto sp1 = make_shared<widget>();
auto sp2 = sp1;

Figure 2(b): Approximate memory layout for Example 2(b).
Note that combining the allocations has two major advantages:
- It reduces allocation overhead, including memory fragmentation. First, the most obvious way it does this is by reducing the number of allocation requests, which are typically more expensive operations. This also helps reduce contention on allocators (some allocators don’t scale well). Second, using only one chunk of memory instead of two reduces the per-allocation overhead. Whenever you ask for a chunk of memory, the system must give you at least that many bytes, and often gives you a few more because of using fixed-size pools or tacking on housekeeping information per allocation. So by using a single chunk of memory, we tend to reduce the total extra overhead. Finally, we also naturally reduce the number of “dead” extra in-between gaps that cause fragmentation.
- It improves locality. The reference counts are frequently used with the object, and for small objects are likely to be on the same cache line, which improves cache performance (as long as there isn’t some thread copying the smart pointer in a tight loop; don’t do that).
As always, when you can express more of what you’re trying to achieve as a single function call, you’re giving the system a better chance to figure out a way to do the job more efficiently. This is just as true when inserting 100 elements into a vector using a single range-insert call to v.insert( first, last ) instead of 100 calls to v.insert( value ) as it is when using a single call to make_shared instead of separate calls to new widget() and shared_ptr( widget* ).
There are two more advantages: Using make_shared avoids explicit new and avoids an exception safety issue. Both of these also apply to make_unique, so we’ll cover them under #3.
3. Why should you almost always use make_unique to create an object to be initially owned by a unique_ptr? Explain.
As with make_shared, there are two main cases where you can’t use make_unique to create an object that you know will be owned (at least initially) by a unique_ptr: if you need a custom deleter, or if you are adopting a raw pointer.
Otherwise, which is nearly always, prefer make_unique.
Guideline: Use make_unique to create an object that isn’t shared (at least not yet), unless you need a custom deleter or are adopting a raw pointer from elsewhere.
Besides symmetry with make_shared, make_unique offers at least two other advantages. First, you should prefer use make_unique<T>() instead of the more-verbose unique_ptr<T>{ new T{} } because you should avoid explicit new in general:
Guideline: Don’t use explicit new, delete, and owning * pointers, except in rare cases encapsulated inside the implementation of a low-level data structure.
Second, it avoids some known exception safety issues with naked new. Here’s an example:
void sink( unique_ptr<widget>, unique_ptr<gadget> );
sink( unique_ptr<widget>{new widget{}},
unique_ptr<gadget>{new gadget{}} ); // Q1: do you see the problem?
Briefly, if you allocate and construct the new widget first, then get an exception while allocating or constructing the new gadget, the widget is leaked. You might think: “Well, I could just change new widget{} to make_unique<widget>() and this problem would go away, right?” To wit:
sink( make_unique<widget>(),
unique_ptr<gadget>{new gadget{}} ); // Q2: is this better?
The answer is no, because C++ leaves the order of evaluation of function arguments unspecified and so either the new widget or the new gadget could be performed first. If the new gadget is allocated and constructed first, then the make_unique<widget> throws, we have the same problem.
But while just changing one of the arguments to use make_unique doesn’t close the hole, changing them both to make_unique really does completely eliminate the problem:
sink( make_unique<widget>(), make_unique<gadget>() ); // exception-safe
This exception safety issue is covered in more detail in GotW #56.
Guideline: To allocate an object, prefer to write make_unique by default, and write make_shared when you know the object’s lifetime is going to be managed by using shared_ptrs.
4. What’s the deal with auto_ptr?
auto_ptr is most charitably characterized as a valiant attempt to create a unique_ptr before C++ had move semantics. auto_ptr is now deprecated, and should not be used in new code.
If you have auto_ptr in an existing code base, when you get a chance try doing a global search-and-replace of auto_ptr to unique_ptr; the vast majority of uses will work the same, and it might expose (as a compile-time error) or fix (silently) a bug or two you didn’t know you had.
Acknowledgments
Thanks in particular to the following for their feedback to improve this article: celeborn2bealive, Andy Prowl, Chris Vine, Marek.

One big downside of make_shared() is that it doesn’t work with private/protected constructors. We instead have to jump through hoops / define our own factory functions to do this–or at least from what I’ve found so far. The best workaround I’ve found is this: (from https://gist.github.com/RklAlx/6727537)
#include <memory> class CC { public: static std::shared_ptr<CC> CreateCC(int value); class Key { private: friend std::shared_ptr<CC> CC::CreateCC(int value); Key() {} }; CC(const Key&, int y); ~CC(void); void Show(); private: int y; }; std::shared_ptr<CC> CC::CreateCC(int x) { return std::make_shared<CC>(CC::Key(),x); } CC::CC(const Key& rk, int xy) { y = xy; } CC::~CC(void) { } void CC::Show() { printf("Value: %d\n", y); }make_shared seems pretty broken in this case. Is there a better way to make this work? I wasn’t able to get “friend” to work for this–maybe some one here “haz teh codez”. However, this SO post at least suggests that “friend” is not a good solution anyway:
http://stackoverflow.com/questions/8147027/how-do-i-call-stdmake-shared-on-a-class-with-only-protected-or-private-const/8147213#8147213
Thoughts?
Thanks.
Ah, I see. My confusion came from the fact, that the arguments to a function are described in the standard as “a comma separated list of initilizer-clauses”.
In appendix A (Grammar summary), an initializer-clause is expressed as:
initializer-clause: assignment-expression braced-init-listand “assignment expression” goes all the way down to “expression , assignmend-expression”:
assignment-expression: conditional-expression logical-or-expression assignment-operator initializer-clause throw-expression assignment-operator: one of = *= /= %= += -= >>= <<= &= ˆ= |= expression: assignment-expression expression , assignment-expressionNote the comma in the last line: “expression , assignment-expression”. To my understanding, that comma really is the comma-operator, right?
So in your example, when adding additional params, e.g. f( (a,b) , c), then (a , b) would make a comma-expression, while the second comma is just a more or less meaningless character (besides the fact that it separates initializers.
So, what I did was confusing the “meaningless” comma in “comma-separated list of initializer-clauses” with the comma in the grammar of expressions.
Last question: Is this a typical standard notation? Does a sentence like “a list of items seperated by comma” in the standard always refer to a “meaningless” comma, not an “expression comma”?
Not all commas are the comma operator.
In an ordinary expression like x=(a,b,c), that’s the comma operator, and yes it could invoke an overloaded comma operator.
In a function call like f(a,b,c), however, the (a,b,c) is a parameter list and that comma is not the comma operator. If you wanted the comma operator there could express that, but it would require another set of parens. For example, if you wanted to make the first comma use a comma operator, you could write: g((a,b),c).
According to ISO/IEC N3690, §1.9
Operators can be regrouped according to the usual mathematical rules ONLY WHERE THE OPERATORS REALLY ARE ASSOCIATIVE OR COMMUTATIVE.
So let me write the following expression…
…a bit more verbose as pseudo-code:
Note that the function call operators () have highest precedence in this expression. According to the standard, an implementation is allowed to evaluate the left side of the comma before or after the right side of the comma, but it is not allowed to overrule the precedence of the stronger binding operator () and the weaker binding comma operator.
At least, that’s my understanding :-)
@Volker Diesel
In addition to my previous post (I hope it succeeded, because I don’t see it there)
void func(const std::string & arg1, const std::string & arg2); void caller() { func("Hello", "world"); }When you create a std::string object, it will (possibly) allocate the memory INSIDE the constructor, which means the exception safety issue must be dealt there.
When you write:
void func(std::shared_ptr arg1, std::shared_ptr arg2); void caller() { // BEFORE func(shared_ptr<C>{new C{}}, shared_ptr<C>{new C{}}); // AFTER }The allocation is done NOT inside the shared_ptr constructor.
It is done somewhere BEFORE the shared_ptr constructor is called,t hat is, somewhere in the function “caller”.
Somewhere is the source of the “problem”, because we can’t know for sure where. We only know it is done AFTER the full-expression that precedes the “func” function call expression, BEFORE we effectively enter the “func” function, and BEFORE we enter the shared_ptr constructor.
This is the point of the make_shared and make_unique function: To make sure that the actual allocation is done in a controlled setting, that is, INSIDE the make_* function, where its exception safety can be controlled.
@Volker Diesel:
I know this is an argument of authority, but I guess that when one of the member of the C++ standardization committee says:
Then perhaps you should consider the possibility he/she is right. (I know I would).
:-)
Using your compiler does not mean your reasoning is right. It only means that your example and your belief of how it should behave correlates, nothing more.
But, for the sake of not appearing like “that guy in the classroom telling you to blindly follow the teacher’s advice”, I’ll eat my own dog food, and I’ll try to see if I can by myself find in the C++ standard the exact quotes about your problem because the truth is, I don’t know.
So…
Standardese Interpretation
That is an assertion that should have backed up with a quote of the standard.
I searched a bit, and found none.
Note that I am not a language lawyer, and I am quite unfamiliar with the standard’s wordings and style. Which means everything I could write below could be wrong. Someone with more experience should validate that.
Still, I searched, and I found at 1.9/15 (n3797 draft for C++14):
As I understand it, when you evaluate argument A and argument B, the computations (plural forms) to evaluate A are unsequenced in regard to the computations (plural forms) to evaluate B. (the plural form is important, because it acknowledges that there can be multiple computations and side effects for one argument evaluation)
Now, the signification of unsequenced, and its consequence even within one thread:
If I understood correctly, this means that the evaluation of two arguments in a function call are not sequenced, and thus, can overlap.
The keyword is overlap, here. If I understand it correctly, it means, for example in the following code:
… that the implementation could well decide to first execute “a + b”, and put the result in a temporary a2, then execute “d + e”, put the result in a temporary d2, then execute “d2 + f”, and then “a2 + c”… Or any other combination.
Application on your shared_ptr example
Now that we understand expression overlaping, we can look at the shared_ptr construction.
This is a bit devious because when you write “new A()” (there is no arguments for simplicity’s sake), you are doing (at least) two things in one apparent expression:
1 – allocate memory
2 – launch the constructor at that allocated address.
This example with new is explicitly mentioned in 1.9/15, and it redirect us to 5.3.4, which describes the unary expression “new”. In that section, there is a very interesting subsection 5.3.4/18:
(the section is a bit more complex, and handle what happens with arguments, that is: arguments can be evaluated after or before [but not overlaping] the memory allocation, but before construction call, of course)
So, when you write (I simplified your example):
func(shared_ptr{new C{}}, shared_ptr{new C{}]);… what you have on your hands is the following actions:
1.a – allocation of memory for the first C object
1.b – construction of the first C object
1.c – construction of the first shared_ptr
2.a – allocation of memory for the second C object
2.b – construction of the second C object
2.c – construction of the second shared_ptr
So while 1.a should happen before 1.b, and 1.b before 1.c, and 2.a should happen before 2.b, and 2.b before 2.c, the standard specifically says that the two operations 1 and 2 could overlap, which means it could be executed as:
1.a – allocation of memory for the first C object
2.a – allocation of memory for the second C object
1.b – construction of the first C object
2.b – construction of the second C object
1.c – construction of the first shared_ptr
2.c – construction of the second shared_ptr
And this is where it becomes a problem, because both X.a and X.b could throw, and sometimes, they could throw before any shared_ptr had the chance of taking ownership of any pointer.
If you add arguments to the constructors, then the problem goes even more complicated (I won’t go there, because I believe my point is done)
Conclusion
Unless I messed up somewhere (could someone validate my [naive] reasoning?), I believe I offered the proof your reasoning is wrong, and that you always need to use make_* functions to make sure your code is exception safe.
You could ask why this is so complicated, and why some parts are left unspecified. My guess is performance. By letting the compiler implementers more freedom on a few topics we should usually not care about, we let them more optimization options.
Thanks,
“No matter, in which order arguments are evaluated, and no matter which of the constructors of class C throws, the first two calls are always leak-safe. The reason is, that the entire expression of each single argument is first fully evaluated, before the next argument evaluation starts. This means, after one argument is full evaluated, a temporary shared_ptr object already exists, that holds the pointer to new C object. If during evaluation of the next argument an exception is thrown, that temporary object is destroyed and so is the newly created C object.”
Are you basing this assertion on just your experimentation, or do you have actual requirements from the standard that says that one entire parameter expression has to be fully evaluated before another can be started?
Are you *absolutely sure* that the compiler is not allowed to take this:
func(shared_ptr{new C{args1}}, shared_ptr{new C{args2}]);and make it work like this:
C *t1 = new C{args1}; C *t2 = new C{args2}; shared_ptr<C> p1(t1); shared_ptr<C> p2(t2); func(p1, p2);or even this:
C *t2 = new C{args2}; C *t1 = new C{args1}; shared_ptr<C> p2(t2); shared_ptr<C> p1(t1); func(p1, p2);The reason that make_shared(args1) works is that there is no way for the compiler to move code from inside make_shared before or after the call to make_shared itself.
“Clearly, for such calls to work, the compiler must generate temporary std::string objects, and clearly std::string’s constructor might allocate memory and therefore throw bad_alloc. ”
That’s different. You aren’t allocating memory and passing it to the std::string constructor, it’s the std::string constructor that is allocating the memory.
Here are my code snippets again, this time enclosed in code blocks. See also my additional comment at the bottom of this posting.
void func(shared_ptr<C> a, shared_ptr<C> b); // function declaration func(make_shared{args1}, make_shared{args2}); // call with make_shared, no leak. func(shared_ptr{new C{args1}}, shared_ptr{new C{args2}]); // call with explicitly constructed shared_ptr, no leak. func(new C{args1}, new C{args2}); // call with naked new. compile error: no implicit conversion.Example program:
#include <memory> #include <iostream> #include <exception> class Ex : public std::logic_error { public: Ex(const std::string & what) : std::logic_error{what} {} }; class Data { public: Data(const std::string & data) : m_data(data) { std::cout << "Data::Data(" << m_data << ")" << std::endl; } ~Data() { std::cout << "Data::~Data(" << m_data << ")" << std::endl; }; const std::string & data() const { return m_data; } private: std::string m_data; }; class C { public: C(const std::string & name, bool throwSomething = false) : m_data{name} { std::cout << "C::C(" << m_data.data() << ")" << std::endl; if ( throwSomething ) { throw Ex{m_data.data()}; } } ~C() { std::cout << "C::~C(" << m_data.data() << ")" << std::endl; } private: Data m_data; }; void f(std::shared_ptr<C> a1, std::shared_ptr<C> a2) {} void test(bool useMakeShared, bool throwInFirst, bool throwInSecond) { std::cout << std::boolalpha << "*** Test: useMakeUnique= " << useMakeShared << ", throwInFirst=" << throwInFirst << ", throwInSecond=" << throwInSecond << std::endl; try { if ( useMakeShared ) { f(std::make_shared<C>("first", throwInFirst), std::make_shared<C>("second", throwInSecond)); } else { f(std::shared_ptr<C>{new C{"first", throwInFirst}}, std::shared_ptr<C>{new C{"second", throwInSecond}}); } } catch ( const std::exception & ex ) { std::cout << "Caught exception: " << ex.what() << std::endl; } } int main() { // test(false, false, false); // test(true, false, false); // test(false, false, true); // test(true, false, true); test(false, true, false); test(true, true, false); // test(false, true, true); // test(true, true, true); }Additional comment… consider a much more trivial and frequently used example:
void func(const std::string & arg1, const std::string & arg2); void caller() { func("Hello", "world"); }I guess, we all have already written code like this without scratching out heads because of exception (un)safety (even in my example program above, I use such calls when creating objects of class “C” with c-style strings like “first” and “second”).
Clearly, for such calls to work, the compiler must generate temporary std::string objects, and clearly std::string’s constructor might allocate memory and therefore throw bad_alloc. What, if that happens? Again, the answer is: nothing special and nothing wrong.For each argument, temporary std::string objects are placed on the stack. If that is successfully done, the function call is made, and the called function takes the temporaries on the stack as its arguments. If the creation of one of the temporaries fails (e.g. due to bad_alloc), the stack is unwound and all temporaries that have already been created are properly destroyed.
…and sorry… I really should have read first how to format code blocks :-)
I agree with most of the things posted here, but I’d like to point out one wrong information as well: There is no problem with memory leaks when passing multiple smart pointers to a function! No matter how it is done, it’s always leak-safe. Consider:
void func(shared_ptr a, shared_ptr b); // function declaration
func(make_shared{args1}, make_shared{args2}); // call with make_shared, no leak.
func(shared_ptr{new C{args1}}, shared_ptr{new C{args2}]); // call with explicitly constructed shared_ptr, no leak.
func(new C{args1}, new C{args2}); // call with naked new. compile error: no implicit conversion.
No matter, in which order arguments are evaluated, and no matter which of the constructors of class C throws, the first two calls are always leak-safe. The reason is, that the entire expression of each single argument is first fully evaluated, before the next argument evaluation starts. This means, after one argument is full evaluated, a temporary shared_ptr object already exists, that holds the pointer to new C object. If during evaluation of the next argument an exception is thrown, that temporary object is destroyed and so is the newly created C object.
Here’s an example program, that demonstrates this behavior:
// =========================================
#include
#include
#include
class Ex : public std::logic_error
{
public:
Ex(const std::string & what) : std::logic_error{what} {}
};
class Data
{
public:
Data(const std::string & data) : m_data(data) { std::cout << "Data::Data(" << m_data << ")" << std::endl; }
~Data() { std::cout << "Data::~Data(" << m_data << ")" << std::endl; };
const std::string & data() const { return m_data; }
private:
std::string m_data;
};
class C
{
public:
C(const std::string & name, bool throwSomething = false) : m_data{name}
{
std::cout << "C::C(" << m_data.data() << ")" << std::endl;
if ( throwSomething )
{
throw Ex{m_data.data()};
}
}
~C() { std::cout << "C::~C(" << m_data.data() << ")" << std::endl; }
private:
Data m_data;
};
void f(std::shared_ptr a1, std::shared_ptr a2) {}
void test(bool useMakeShared, bool throwInFirst, bool throwInSecond)
{
std::cout << std::boolalpha <<
"*** Test: useMakeUnique= " << useMakeShared <<
", throwInFirst=" << throwInFirst <<
", throwInSecond=" << throwInSecond << std::endl;
try
{
if ( useMakeShared )
{
f(std::make_shared(“first”, throwInFirst), std::make_shared(“second”, throwInSecond));
}
else
{
f(std::shared_ptr{new C{“first”, throwInFirst}}, std::shared_ptr{new C{“second”, throwInSecond}});
}
}
catch ( const std::exception & ex )
{
std::cout << "Caught exception: " << ex.what() << std::endl;
}
}
int main()
{
// test(false, false, false);
// test(true, false, false);
// test(false, false, true);
// test(true, false, true);
test(false, true, false);
test(true, true, false);
// test(false, true, true);
// test(true, true, true);
}
// =========================================
The interesting case in my environment is case number three (construction of first argument throws), because arguments are evaluated right to left on my system.
Here's the output:
*** Test: useMakeUnique= false, throwInFirst=true, throwInSecond=false
Data::Data(second)
C::C(second)
Data::Data(first)
C::C(first)
Data::~Data(first)
C::~C(second)
Data::~Data(second)
Caught exception: first
*** Test: useMakeUnique= true, throwInFirst=true, throwInSecond=false
Data::Data(second)
C::C(second)
Data::Data(first)
C::C(first)
Data::~Data(first)
C::~C(second)
Data::~Data(second)
Caught exception: first
First, as you can see, the output is identical, no matter whether make_shared is used or shared_ptr explicitly constructed. Second, the the output show, that there's no leak.
Construction of arguments:
1) Data member m_data of seconds argument is fully constructed.
2) C part for second argument is fully constructed. Had I modified class shared_ptr to ouput something in its constructor, at that point we would see this output, namely the construction of a temporary shared_ptr holding the newly created second argument.
3) Data member m_data of first argument is fully constructed.
4) C's constructor body of first argument throws.
Destruction after exception.
1) The Data member m_data of the first argument is destroyed.
2) The "C" part of the first argument is NOT destroyed, because the object has not been fully constructed.
3) The "C" part of the second argument is destroyed.
4) The data member m_data of the second argument is destroyed. Again, had I modified class shared_ptr to output something, we would see output from ~shared_ptr of temporary object created for second argument here.
Having a pointer suddenly becoming null is not limited to C++’s unique_ptr.
C++’s shared_ptr and even C#/Java’s references can become null, just by assigning null to them, or even (in C++/C#), passing them as non-const references to functions (after that call, you can’t guarantee the pointer doesn’t point to another object… or to null).
We do use smart pointers to control lifetime (or more precisely, to give exclusive or shared ownership), but the lifetime of an object is a design problem which must be solved before coding.
This is all about RAII: Make sure the lifetime of your object is tied, directly or indirectly, to a level of the stack. Above that level, your object is always valid. Under that level, your object isn’t anymore. And in practice (my own professional experience), it works.
IMHO, ownership of an object can be determined by how it is passed around (in order of preference):
– a raw pointer: There is no ownership involved. The object is valid (or the pointer is null). Pass it by value.
– a unique_ptr: Usually pass it by value (using std::move), which gives ownership.
– a shared_ptr: Usually pass it by value, which shares ownership. If possible, use weak_ptr for weak shared ownership.
Passing a (smart or not) pointer by reference (or const reference) blurs a code review, for the reasons you mention (it is not clear if the pointer is still the same after the function call), unless the function is quite clear about what it is doing (e.g. the C++ swap function, or the C# TryParse function).
The return value is another problem: After all, a function could return a pointer (or a reference) to an object it owns, thus insuring a dangling pointer/reference return. In my own experience, returning a dangling pointer/reference usually happens on object declared on the stack (usually in the very same function). This is a newbie mistake, easily learned.
The solution is NOT relying on shared_ptr to enable a “I don’t need to care” mode where all objects are shared by everyone to play with (this is what global objects are for, and last time I checked, global objects are supposed to be an antipattern).
The solution is a design solution: Don’t return a pointer to something that wasn’t given to you as a pointer by the calling function (if it was given to you as a pointer, then it is owned by a level lower in the stack, so it is still alive after the return), unless you can guarantee the object’s lifetime goes beyond the function call.
Now, your solution is to use shared_ptr everywhere. While I did show above even shared_ptr can point to null at one moment’s notice, shared_ptr have other problems. For example, let’s say you want to close that connection to a distant server. This means calling that “close()” method of your shared object. The consequence is that every part of the code having a shared_ptr to that connection will now have an unusable object because you can’t anymore use it for anything. Isn’t that the problem you wanted to avoid the first place?
And this is not limited to C++: C# and Java can have the same problem, and both ended with RAII-like features (the using/disposable for C#, try-with-resource/autoclosable) in addition to their massively shared ownership semantics.
So, in the end, yes, you always have to think about object lifetimes. But this is a design problem. Not a smart pointer problem. The solution is a design solution. And it will involve using this or that kind of pointer which is best adapted to that decision.
The semantics of unique_ptr are more complex than shared_ptr. You have to use std::move with it; after you do so, the scope in which that was done effectively has a null pointer that can be accidentally used. Shared_ptr has neither of these problems. These things suggest the opposite conclusion: prefer shared_ptr. Also, I see that coders seem to use unique_ptr to control lifetime, but feel free to pass around raw pointers and references as if that were safe and maintainable. If various places in the code are going to use a smart pointer, it should be treated as shared.
Is there any helper template to relieve pain from make_unique to make_shared, if I decide to change from unique_ptr to shared_ptr later?
For example,
template <class SP> class smart_ptr_switch { template <class... Args> static SP make_smart(Args&&... args) { if (SP is some kind of unique_ptr<T>) { return std::make_unique<T>(new T(std::forward<Args>(args)...)); } else if (SP is some kind of shared_ptr<T>) { return std::make_shared<T>(new T(std::forward<Args>(args)...)); } else { static_assert ??? } } };So I can typedef my_smart_pointer to a std::unique_ptr first. If later I change typedef my_smart_pointer to a std::shared_ptr, I don’t need to change all std::make_unque to std::make_shared.
If I call smart_ptr_switch::make_smart(…) and typedef std::unique_ptr my_smart_pointer, this method will return a result from make_unique.
If I call smart_ptr_switch::make_smart(…) and typedef std::shared_ptr my_smart_pointer, this method will return a result from make_shared.
@Marco
You are correct that the block cannot be released until the last shared_ptr/weak_ptr is destroyed. However, the object’s destructor is invoked when the last shared_ptr is destroyed.
@Herb: Another question popped up when looking at figure 2(b): make_shared allocates one single block of memory holding the strong and weak reference counters and the object itself. So if there are no shared_ptr left, but at least one weak_ptr, the whole block cannot be released, correct? So if one’s handling large objects and using shared_ptr the recommendation should be not to use make_shared? Or is there something I’m missing?
@Marco: Yes, that’s the kind of case the internal synchronization on the refcount is needed for — the user is allowed to do concurrent operations where not all are const on different objects, just not on the same object. The same case arises with polygon::area when two threads do const operations but might modify mutable state.
@herb tnx for the A,
now when you explain it is doh. :D
like Scott says shared prt is actually ptr_to_shared :D
@Herb: Thank you very much for your explanations. I’m still not sure we are talking about the same thing.
class A
{ public:
int GetValue() const;
};
There cannot be any writers, so that is no concern here and would have to be handled externaly, anyway. But what if two threads do the following at exactly the same time:
shared_ptr sp1(make_shared()); // shared ptr in T1.
weak_ptr wA(sp1); // weak ptr in T2.
T1: sp1 = nullptr;
T2: shared_ptr sp2(wA.lock());
So, both threads keep a smart pointer to the same data element, one shared and one weak. At the moment T1 releases its reference T2 tries to get a new reference. This means that T1 is changing the strong refs counter at the very moment T2 is changing it as well. Do the reference counters have a barrier that guarantees thread safety in this context?
I’m looking forward to the GotW on thread safety. Thanks again!
When I implement a class deriving from enable_shared_from_this, I usually make all constructors private and add static factory functions that create and return shared pointers to the class. As the constructors are private I cannot use make_shared in these factory functions but I have to resort to using new. At least this is true for boost::make_shared. I haven’t found a way like making some function or function template instantiation a friend of the said class to be able to use make_shared. Do I miss something?
@nosenseetal: No, you can’t use a unique_ptr or a shared_ptr that way. A given shared_ptr object is like any other normal object — if you have multiple concurrent accesses and one is a writer (non-const) you have to protect it using a mutex or other synchronization. What synchronization shared_ptr does internally is to protect the reference counts when they are read/written via *different* shared_ptr objects, because the caller can’t possibly know which shared_ptrs share state and figure out the right external synchronization, nor should he. The same issue arises when two strings share implementations because of refcounted copy-on-write, or with the polygon::area discussed in GotW #6b.
@herb
what about my example of “spinlock” on up and sp?
Isnt sp version correct program, while up is UB?
Or maybe sp counter is incremented with non_seq_const mem order ?
btw I think you need to mention bitfields as odd(if you get how hw works not so odd) exception when talking about thread safety.
@Marek: Yes, unspecified. Thanks, updated.
@Tom: I can’t easily share that, but you could try something like this (untested code follows, yours to test and fix).
template<typename T, typename A1> std::unique_ptr<T> make_unique( A1&& a1 ) { return std::unique_ptr<T>( new T( std::forward<A1>(a1) ) ); } template<typename T, typename A1, typename A2> std::unique_ptr<T> make_unique( A1&& a1, A2&& a2 ) { return std::unique_ptr<T>( new T( std::forward<A1>(a1), std::forward<A2>(a2) ) ); } // etc. for as many constructor parameters as you want to support@andyprowl, @Chris Vine: Right you are. The issue is as described, now the spelling is fixed, thanks.
@Marco, @nosenseetal: Virtually all types, including shared_ptr (and vector, and other types) are just as thread-safe as any old type including int — safe for concurrent reads (const operations) but require external synchronization if you know the object is shared and will have multiple threads trying to use it concurrently and at least one is a writer. The reason GotW #6b’s polygon needed “some” internal synchronization is the same reason std::shared_ptr needs “some” internal synchronization: to synchronize the under-the-covers shared state the caller can’t see and that isn’t covered by the usual external synchronization. The easy way to spot such *internal* shared state is that it’s shared state that can be modified in a const operation. That needs internal synchronization so that the caller’s usual external-sync duty of care is sufficient.
The only types that are not like that are basically those designed to perform inter-thread communication and synchronization, like mutex and condition_variable and atomic.
This is a FAQ, alas. I need to write that GotW on thread safety. Maybe later this summer…
@celeborn2bealive: You’re right, I’ve updated the wording to try to make these be phrased as “prefer” rather than “always.” There are two parts to this: 1. unique_ptr and shared_ptr are to be preferred whenever possible, but you might have a reason to use another smart pointer type, such as legacy or for custom behavior you can’t achieve with deleters and allocators on unique_ptr and shared_ptr. 2. make_unique and make_shared also should be preferred wherever possible, but you might have a reason not to use make_unique or {make|allocate}_shared if you need a custom deleter or are adopting a pointer. I’ve now added this to the discussion, including mentioning allocate_shared. Thanks!
“c/c++ malloc works very deterministic and there is no intelligence. first free block that fits the size or more (requested) will be returned.”
“system tries to minimize fragmentation”
None of this is true. C++ does not dictate how the memory allocation routines should allocate their memory. This is completely implementation defined (as long as certain rules are followed regarding alignment).
On my highly specialized platform we wrote a custom allocator that has zero overhead for the common allocation sizes while maintaining the normal overhead for all other allocation sizes. We also don’t have a fragmentation problem with these common sizes.
@Andrew Marshall weak_ptr gets notified when the object is deleted and will prevent you from accessing it where a raw pointer will let you do anything with the already deleted object sending you in undefined land.
@Herb
“If you use make_shared to allocate the object and the shared_ptr all in one go, then the implementation can fold them together in a single allocation”
could you please elaborate more on the impl. details, how?
looking at VS2012 ans std::make_shared
I see 2 new calls:
new _Ref_count_obj(LIST(_FORWARD_ARG)); //inside make_shared
::new ((void *)&_Storage) _Ty(LIST(_FORWARD_ARG));//inside _Ref_count_obj
@Marco
“The two memory blocks will in general have very different sizes ” – thats ok.
“may life in far far away areas of the memory because the system tries to minimize fragmentation” – c/c++ malloc works very deterministic and there is no intelligence. first free block that fits the size or more (requested) will be returned. AFIK there is no such thing: “system tries to minimize fragmentation”
now considering the ‘administration’ data along each shared_ptr is minimal , chances are it wont cause allocation to come from another block, but most likely same block will fit the two counts and the data you ask.
but now that I explained what malloc will do. YES I can answer my own question, that it is indeed possible to defragment the mem, regardless whether you have a malloc in between !
@pip010: The two memory blocks will in general have very different sizes and may life in far far away areas of the memory because the system tries to minimize fragmentation.
well, instead:
void sink( unique_ptr, unique_ptr );
unique_ptr arg1(new widget{});
unique_ptr arg2(new gadget{});
//–exception line
sink(arg1,arg2);
so here it goes. same exception-safety :)
about: “It reduces allocation overhead, including memory fragmentation”
correct me if I’m mistaken but in order to really create fragmentation.
something needs to allocate between new gadget() and new unique_ptr().
is that even possible? if we assume we are in 1process-1thread app?
same goes for locality?
> The answer is no, because C++ leaves the order of evaluation of function arguments undefined…
I think it is unspecified not undefined.
If I’m not mistaken, the smart and weak ptr works like this:
Let say we have a smart and a weak ptr pointing to the same object.
Now we destroy the smart_ptr: since no other owning ptr is present, it call’s the destructor of the pointed object, and it even deallocates it. But it won’t deallocate the control block.
Now we destroy the weak_ptr, and it will deallocate the control block.
But here is the catch: If we used make_shared, the shared_ptr destructor can’t deallocate the area of the pointed object, only the weak_ptr will deallocate it (when it gets rid of the control block).
Am I right?
Given that make_unique and make_shared can aggregate the memory allocation for the ref –counting together with that for the pointed at T, how does that play with class member operator::new() and operator::delete()? Depending on how this is managed you are either going to inherit the custom operators (which would be bad if it an allocator that assumes it only ever has to allocate sizeof(T) objects), or you are going to entirely circumvent efforts by a class designer to provide specific allocation facilities (which might lead to memory fragmentation and poor performance due to broken cache coherency, or simple failure to work if all members of a class are supposed to be in some shared memory pool).
It would seem to be worthwhile pointing out that mixing classes with custom allocators together with make_shared or make_unique is a Bad Idea.
To solve the problem for shared_ptr there is allocate_shared() that will take an allocator for generating shared_ptr which will get the same result as a custom operator::new()/operator ::delete() set (with a little rewriting) , However the only references I can find to “allocate_unique” are to Oracle DBMS systems…. Is this another candidate for the “Oops, we should have done that” C++14 list, or are there some subtleties I haven’t considered?
Thanks for the answer. I was referring to the reference counter. Good to know it is thread safe. We have had our own implementation of smart and weak pointers. Now we’re about to go to VS 2012, so I’m looking forward using all these great new features!
“sink( new widget{}, new gadget{} ); // Q1: can you spot the problem?”
The principal problem with this is that it will not compile, because unique_ptr’s constructor taking a pointer is explicit.
sink(std::unique_ptr<widget>{new widget{}}, std::unique_ptr<gadget>{new gadget{}});will compile but is not exception safe. Not only is the order of evaluation of the arguments unspecified, but the compiler is entitled to to construct gadget, and then before initializing the unique_ptr to take gadget construct widget, and only then construct the unique_ptr objects. Of course, it would be a very odd compiler which did it this way. Allowing this loose evaluation is in my view a defect in the standard, but I know that most others disagree.
Great article but I have one question. I always assumed that you cannot make a vector of unique pointers of objects because the vector demands that an object always be copyable. And unique pointers are definitely not copyable. Perhaps the move semantics in C++ 11 Are what enables the creation of a vector of unique pointers.
Responding to celeborn2bealive
“when you allocate memory from a dynamic library, that memory must be freed in the code of the library.”
says who? the C++ library says nothing about that. I know that with Visual C++, given certain compiler flags, that might be true. But it certainly isn’t true on any platform I use.
If that is true on your platform, then you have some choices. My preferred method is to use an object factory which returns a shared_ptr. The shared_ptr, at construction time, encodes a pointer to the destruction function. The object factory then both constructs the new object AND encodes the destructor function, for free. When the shared_ptr’s counts go to 0, the caller, even if in a different library/toolkit/translation unit, still calls back into the same TU as the object factory to free the memory. Again, this happens automatically because the destructor function is populated in the same TU as the initial construction of the referenced object in the shared_ptr.
nosenseetal: I think that you need to use the overloads of atomic_load and atomic_store that take shared_ptr for that to be acceptable. i.e. I’m pretty sure that individual instances of shared_ptr are not thread safe, only the reference counts that may be shared between multiple instances of a shared_ptr are.
I think the first two calls to sink() (in the answer to Q3) should not compile, since the constructor of unique_ptr that accepts a raw pointer is marked as explicit. Am I overlooking something?
What happens if the class being instantiated with make_shared has class-specific new and delete operators? Will make_shared use that one (and thus still make a separate allocation for the control block)?
@herb
One of the nice things in C++ is that you don’t pay for something you do not use.
However, using shared_ptr in the context of a single threaded env/module incur the atomic op overhead.
It might be negligible in some scenarios, but in others, it might be a good reason not to use it.
Any thoughts about it? Are we going to see a shared_ptr w/o locks somewhere in the future?
@Anders Dalvander
A solution is to write your own “make_my_shared” insuring it will be expection safe and the new will be done outside the standard make_shared.
This way, you keep the exception safety and follow the “don’t-write-naked-new” guideline, all the while separating the memory for the reference counters from the memory for your very-large-object.
make_shared can be wasteful if you have large objects and weak_ptr to these shared objects as the memory for the large object cannot be deallocated before the last weak_ptr has been destroyed. Sometimes it is better to use new instead of make_shared.
@herb
There are three major reasons to say “when in doubt, prefer unique_ptr.”
well I have one reason to prefer SP:
by default it is “thread safe” (big “”)
aka afaik
(this is ok, but wasteful)
while (!sp)
{
}
//use sp
(this is not ok)
while (!up)
{
}
//use up
(up, sp set in other thread)
Am I wrong to think that SP is thread “safer” :P than UP ?
@marco
yes but that doesnt mean that what it points to is magically “locked” when you use it. :)
boost sp has option to disalbe thread safety
If your program is single-threaded and does not link to any libraries that might have used shared_ptr in its default configuration, you can #define the macro BOOST_SP_DISABLE_THREADS on a project-wide basis to switch to ordinary non-atomic reference count updates.
One thing we were discussing about a lot: are c++ shared_ptr threadsafe?
Hi Herb, is there any chance you could post somewhere your preferred pre ‘Milan’ (variadics) implementation for VS2012 Update 2 MSVC developers who want to use a pseudo blessed implementation of make_unique today?
Very interesting, I love your articles :) But I have a question about make_unique() and make_shared(): If i don’t say bullshit, when you allocate memory from a dynamic library, that memory must be freed in the code of the library. So for exemple if I have a function with the following signature in my library:
I don’t understand how the compiler do things right to release the memory for the Widget in the library code (if it does…) since unique_ptr is a template class and I think its code will be instanciated in the client code.
I know I can provide a custom deleter for the pointer (std::unique_ptr createButton();) to be sure, but in that case I cannot use make_unique() to create it (the same question holds for shared_ptr and it’s Deleter functor).
Thank you for your answer and correct me if I’m wrong :)
What’s the advantage (if any) of weak_ptr over a non-owning raw pointer?
BTW, the reason I’m posting #89 to #91 in faster succession is because we already saw versions of these exactly one year ago, as then-numbered #103 to #105, so some of the comment discussion about them would be duplicated and I also wanted to get more quickly to the solution for the third which I didn’t post last year. I think you’ll see that all three have been considerably updated since the initial three questions and two solutions I posted a year ago — and not just because of make_unique, and its corollary don’t-write-new, but also some other C++14-isms including in the one after this.