Lest people get the wrong idea, I enjoy reading Jeff Atwood’s blog and agree with much of what he writes so entertainingly and provocatively. So far I’ve only responded when I strongly felt differently about something, which has been a grand total of twice now.
So let me also offer an example of something I wholeheartedly agree with. Yesterday, Jeff cited what is also my own favorite Programming Pearls figure:
Despite the enduring wonder of the yearly parade of newer, better hardware, we’d also do well to remember my all time favorite graph from Programming Pearls:
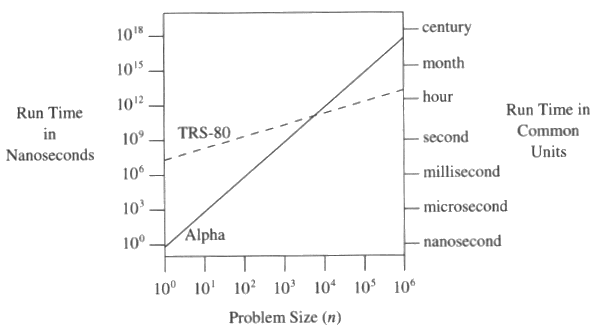
Spot on. If you’re a professional programmer and haven’t read Programming Pearls yet, “run don’t walk” to your bookstore of choice.
Incidentally, just to tie this in to parallel computing as well, Jeff’s article also cites a nice graph of optimizations that improved NDepend:
Patrick Smacchia’s lessons learned from a real-world focus on performance is a great case study in optimization.

Patrick was able to improve nDepend analysis performance fourfold, and cut memory consumption in half. As predicted, most of this improvement was algorithmic in nature, but at least half of the overall improvement came from a variety of different optimization techniques.
As I’ve said many times, measure twice, optimize once: Know when and where to optimize. Profilers are your friend. As Patrick writes:
When it comes to enhancing performance there is only one way to do things right: measure and focus your work on the part of the code that really takes the bulk of time, not the one that you think takes the bulk of time.
And of course, in our ever-more-multicore world, the contribution of parallelization gain will continue to grow and dominate the optimization of CPU-bound code. But as Patrick also notes, realizing that gain is not always trivial:
While we get the 15% gain from between 1 and 2 processors, the gain is almost zero between 2 and 4 processors. We identified some potential IO contentions and memory issues that will require more attention in the future. This leads to another lesson: Don’t expect that scaling on many processors will be something easy, even if you don’t share states and don’t use synchronization.

A few comments about this:
First, constant factors matter. Sometimes, they really, really matter.
Second, problems due to algorithmic complexity can be extremely well-hidden in complex modern software. It might only be in production that you find that you have some operation that takes 1e-9 n^2 time where n is the number of machines in the server farm. (Or, as I discovered once, n^2 in the number of tiers. That one was very subtle.)
Third, you almost never have to code a “standard” algorithm by yourself any more. But when you do, you really do. I’ve only ever had to code a sort algorithm twice. One was in a very small embedded system with little spare memory but N was guaranteed to be fairly small, so Shell sort seemed appropriate. The other was when the sort operation for a DBMS, which is always a special case.
Fourth, and perhaps most importantly: The biggest favour you can give your code, if you want performance, is to design your internal interfaces carefully and unit/mock test everything. Then when you do find a performance problem, you can just replace the offending component and everything should just work.