On Friday, I sat down with Kevin Carpenter to do a short (12-min) interview about my ACCU talk coming up on April 17, and other topics.
Apologies in advance for my voice quality: I’ve been sick with some bug since just after the Tokyo ISO meeting, and right after this interview I lost my voice for several days… we recorded this just in time!
Kevin’s questions were about these topics in order (and my short answers):
Chatting about my ACCU talk topics (safety, and cppfront update)
Is it actually pretty easy to hop on a stage and talk about C++ for an hour (nope; or at least for me, not well)
In ISO standardization, how to juggle adding features vs. documenting what’s done (thanks to the Reddit trip report coauthors!)
ISO C++ meetings regularly have lots of guests, including regularly high school classes (yup, that’s a thing now)
With the winter ISO meeting behind us, it’s onward into spring conference season!
ACCU Conference 2024. On April 17, I’ll be giving a talk on C++’s current and future evolution, where I plan to talk about safety based on my recent essay “C++ safety, in context,” and progress updates on cppfront. I’m also looking forward to these three keynoters:
Laura Savino, who you may recall gave an outstanding keynote at CppCon 2023 just a few months ago. Thanks again for that great talk, Laura!
Björn Fahller, who not only develops useful libraries but is great at naming them (Trompeloeil, I’m looking at you! [sic]).
Inbal Levi, who chairs one of the two largest subgroups in the ISO C++ committee (Library Evolution Working Group, responsible for the design of the C++ standard library) and is involved with organizing and running many other C++ conferences.
Effective Concurrency online course. On April 22-25, I’ll be giving a live online public course for four half-days, on the topic of high-performance low-latency coding in C++ (see link for the course syllabus). The times of 14.00 to 18.00 CEST daily are intended to be friendly to the home time zones of attendees anywhere in EMEA and also to early risers in the Americas. If you live in a part of the world where these times can’t work for you, and you’d like another offering of the course that is friendlier to your home time zone, please email Alfasoft to let them know! If those times work for you and you’re interested in high performance and low latency coding, and how to achieve them on modern hardware architectures with C++17, 20, and 23, you can register now.
Beyond April, later this year I’ll be giving talks in person at these events:
Moments ago, the ISO C++ committee completed its third meeting of C++26, held in Tokyo, Japan. Our hosts, Woven by Toyota, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 220 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 21 nations. That makes it roughly tied numerically for our largest meeting ever, roughly the same attendance as Prague 2020 that shipped C++20 just a few weeks before the pandemic lockdowns. — However, note that it’s not an apples-to-apples comparison, because the pre-pandemic meetings were all in-person, and since the pandemic they have been hybrid. But it is indicative of the ongoing strong participation in C++ standardization.
At each meeting we regularly have new attendees who have never attended before, and this time we welcomed over 30 new first-time attendees, mostly in-person, who were counted above. (These numbers are for technical participants, and they don’t include that we also had observers, including a class of local high school students visiting for part of a day, similarly to how a different local high school class did at our previous meeting in Kona in November. We are regularly getting high-school delegations as observers these days, and to them once again welcome!)
The committee currently has 23 active subgroups, 16 of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their workloads. You can find a brief summary of ISO procedures here.
This week’s meeting: Meeting #3 of C++26
At the previous two meetings in June and November, the committee adopted the first 63 proposed changes for C++26, including many that had been ready for a couple of meetings while we were finishing C++23 and were just waiting for the C++26 train to open to be adopted. For those highlights, see the June trip report and November trip report.
This time, the committee adopted the next set of features for C++26, and made significant progress on other features that are now expected to be complete in time for C+26.
Here are some of the highlights… note that these links are to the most recent public version of each paper, and some were tweaked at the meeting before being approved; the links track and will automatically find the updated version as soon as it’s uploaded to the public site.
Adopted for C++26: Core language changes/features
The core language adopted 10 papers, including the following…
P2573R2 “=delete(“should have a reason”)” by Yihe Li does the same for =delete as we did for static_assert: It allows writing a string as the reason, which makes it easier for library developers to give high-quality compile-time error messages to users as part of the compiler’s own error message output. Thanks, Yihe!
Here is an example from the paper that will now be legal and generate an error message similar to the one shown here:
class NonCopyable
{
public:
// ...
NonCopyable() = default;
// copy members
NonCopyable(const NonCopyable&)
= delete("Since this class manages unique resources, \
copy is not supported; use move instead.");
NonCopyable& operator=(const NonCopyable&)
= delete("Since this class manages unique resources, \
copy is not supported; use move instead.");
// provide move members instead
};
<source>:16:17: error: call to deleted
constructor of 'NonCopyable': Since this class manages unique resources, copy is not supported; use move instead.
NonCopyable nc2 = nc;
^ ~~
P2795R5 “Erroneous behavior for uninitialized reads” by Thomas Köppe is a major change to C++ that will help us to further improve safety by providing a tool to reduce undefined behavior, especially that it removes undefined behavior for some cases of uninitialized objects.
I can’t do better than quote from the paper:
Summary: We propose to address the safety problems of reading a default-initialized automatic variable (an “uninitialized read”) by adding a novel kind of behaviour for C++. This new behaviour, called erroneous behaviour, allows us to formally speak about “buggy” (or “incorrect”) code, that is, code that does not mean what it should mean (in a sense we will discuss). This behaviour is both “wrong” in the sense of indicating a programming bug, and also well-defined in the sense of not posing a safety risk.
…
With increased community interest in safety, and a growing track record of exploited vulnerabilities stemming from errors such as this one, there have been calls to fix C++. The recent P2723R1 proposes to make this fix by changing the undefined behaviour into well-defined behaviour, and specifically to well-define the initialization to be zero. We will argue below that such an expansion of well-defined behaviour would be a great detriment to the understandability of C++ code. In fact, if we want to both preserve the expressiveness of C++ and also fix the safety problems, we need a novel kind of behaviour.
…
Reading an uninitialized value is never intended and a definitive sign that the code is not written correctly and needs to be fixed. At the same time, we do give this code well-defined behaviour, and if the situation has not been diagnosed, we want the program to be stable and predictable. This is what we call erroneous behaviour.
In other words, it is still an “wrong” to read an uninitialized value, but if you do read it and the implementation does not otherwise stop you, you get some specific value. In general, implementations must exhibit the defined behaviour, at least up until a diagnostic is issued (if ever). There is no risk of running into the consequences associated with undefined behaviour (e.g. executing instructions not reflected in the source code, time-travel optimisations) when executing erroneous behaviour.
Adding the notion of “erroneous behavior” is a major change to C++’s specification, that can help not only with uninitialized reads but also can be applied to reduce other undefined behavior in the future. Thanks, Thomas!
Adopted for C++26: Standard library changes/features
The standard library adopted 18 papers, including the following…
In the “Moar Ranges!” department, P1068R11 “Vector API for random number generation” by Ilya Burylov, Pavel Dyakov, Ruslan Arutyunyan, Andrey Nikolaev, and Alina Elizarova addresses the situation that, when you want one random number, you likely want more of them, and random number generators usually already generate them efficiently in batches. Thanks to their paper, this will now work:
std::array<std::uint_fast32_t, arrayLength> intArray;
std::mt19937 g(777);
std::ranges::generate_random(intArray, g);
// The above line will be equivalent to this:
for(auto& e : intArray)
e = g();
In the “if you still didn’t get enough ‘Moar Ranges!’” department, P2542 “views::concat” by Hui Xie and S. Levent Yilmaz provides an easy way to efficiently concatenate an arbitrary number of ranges, via a view factory. Thanks, Hui and Levent! Here is an example from the paper:
std::vector<int> v1{1,2,3}, v2{4,5}, v3{};
std::array a{6,7,8};
auto s = std::views::single(9);
std::print("{}\n", std::views::concat(v1, v2, v3, a, s));
// output: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Speaking of concatenation, have you ever wished you could write “my_string_view + my_string” and been surprised it doesn’t work? I sure have. No longer: P2591R4 “Concatenation of strings and string views” by Giuseppe D’Angelo adds operator+ overloads for those types. Thanks, Giuseppe, for finally getting us this feature!
P2845 “Formatting of std::filesystem::path” by Victor Zverovich (aka the King of Format) provides a high-quality std::format formatter for filesystem paths that addresses concerns about quoting and localization.
A group of papers by Alisdair Meredith removed some (mostly already-deprecated) features from the standard library. Thanks for the cleanup, Alisdair!
P3142R0 “Printing Blank Lines with println”by Alan Talbot is small but a nice quality-of-life improvement: We can now write just println() as an equivalent of println(“”). But that’s not all: See the yummy postscript in the paper. (See, Alan, we do read the whole paper. Thanks!)
Those are some of the “bigger” or “likely of wide interest” papers as just a few highlights… this week there were 28 papers adopted in all, including other great work on extensions and fixes for the C++26 language and standard library.
Aiming for C++26 timeframe: Contracts
The contracts proposal P2900 “Contracts for C++” by Joshua Berne, Timur Doumler, Andrzej Krzemieński, Gašper Ažman, Tom Honermann, Lisa Lippincott, Jens Maurer, Jason Merrill, and Ville Voutilainen progressed out of the contracts study group, SG21, and was seen for the first time in the Language (EWG) and Library (LEWG) Evolution Working Groups proper. Sessions started in LEWG right on the first day, Monday afternoon, and EWG spent the entire day Wednesday on contracts, with many of the members of the safety study group, SG23, attending the session. There was lively discussion about whether contracts should be allowed to have, or be affected by, undefined behavior; whether contracts should be used in the standard library; whether contracts should be shipped first as a Technical Specification (TS, feature branch) in the same timeframe as C++26 to gain more experience with existing libraries; and other aspects… all of these questions will be discussed again in the coming months, this was just the initial LEWG and EWG full-group design review that generated feedback to be looked at. The subgroups considered the EWG and LEWG groups’ feedback later in the week in two more sessions on Thursday and Friday, including in a joint session of SG21 and SG23.
Both SG21 and SG23 will have telecons about further improving the contracts proposal between now and our next hybrid meeting in June.
On track for targeting C++26: Reflection
The reflection proposal P2996R2 “Reflection for C++26” by Wyatt Childers, Peter Dimov, Barry Revzin, Andrew Sutton, Faisal Vali, and Daveed Vandevoorde progressed out of the reflection / compile-time programming study group, SG7, and was seen by the main evolution groups EWG and LEWG for the first time on Tuesday, which started with a joint EWG+LEWG session on Tuesday, and EWG spent the bulk of Tuesday on its initial large-group review aiming for C++26. Then SG7 continued on reflection and other topics, including a presentation by Andrei Alexandrescu about making sure reflection adds a few more small things to fully support flexible generative programming.
Other progress
All subgroups continued progress. A lot happened that other trips will no doubt cover, but I’ll call out two things.
One proposal a lot of people are watching is P2300 “std::execution” (aka “executors”) by Michał Dominiak, Georgy Evtushenko, Lewis Baker, Lucian Radu Teodorescu, Lee Howes, Kirk Shoop, Michael Garland, Eric Niebler, and Bryce Adelstein Lelbach, which was already design-approved for C++26. It’s a huge paper (45,000 words, of which 20,000 words is the standardese specification! that’s literally a book… my first Exceptional C++ book was 62,000 words), so it has been taking time for the Library Wording subgroup (LWG) to do its detailed review of the specification wording, and at this meeting LWG spent a quarter of the meeting completing a first pass through the entire paper! They will continue to work in teleconferences on a second pass and are now mildly optimistic of completing P2300 wording review at our next meeting in June.
And one more fun highlight: We all probably suspected that pattern matching is a “ground-shaking” proposed addition to future C++, but in Tokyo during the pattern matching session there was a literal earthquake that briefly interrupted the session!
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the over 210 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in just three months from now we’ll be meeting again in person + Zoom to continue adding features to C++26. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
Scope. To talk about C++’s current safety problems and solutions well, I need to include the context of the broad landscape of security and safety threats facing all software. I chair the ISO C++ standards committee and I work for Microsoft, but these are my personal opinions and I hope they will invite more dialog across programming language and security communities.
Acknowledgments. Many thanks to people from the C, C++, C#, Python, Rust, MITRE, and other language and security communities whose feedback on drafts of this material has been invaluable, including: Jean-François Bastien, Joe Bialek, Andrew Lilley Brinker, Jonathan Caves, Gabriel Dos Reis, Daniel Frampton, Tanveer Gani, Daniel Griffing, Russell Hadley, Mark Hall, Tom Honermann, Michael Howard, Marian Luparu, Ulzii Luvsanbat, Rico Mariani, Chris McKinsey, Bogdan Mihalcea, Roger Orr, Robert Seacord, Bjarne Stroustrup, Mads Torgersen, Guido van Rossum, Roy Williams, Michael Wong.
Terminology (see ISO/IEC 23643:2020). “Software security” (or “cybersecurity” or similar) means making software able to protect its assets from a malicious attacker. “Software safety” (or “life safety” or similar) means making software free from unacceptable risk of causing unintended harm to humans, property, or the environment. “Programming language safety” means a language’s (including its standard libraries’) static and dynamic guarantees, including but not limited to type and memory safety, which helps us make our software both more secure and more safe. When I say “safety” unqualified here, I mean programming language safety, which benefits both software security and software safety.
We must make our software infrastructure more secure against the rise in cyberattacks (such as on power grids, hospitals, and banks), and safer against accidental failures with the increased use of software in life-critical systems (such as autonomous vehicles and autonomous weapons).
The past two years in particular have seen extra attention on programming language safety as a way to help build more-secure and -safe software; on the real benefits of memory-safe languages (MSLs); and that C and C++ language safety needs to improve — I agree.
But there have been misconceptions, too, including focusing too narrowly on programming language safety as our industry’s primary security and safety problem — it isn’t. Many of the most damaging recent security breaches happened to code written in MSLs (e.g., Log4j) or had nothing to do with programming languages (e.g., Kubernetes Secrets stored on public GitHub repos).
In that context, I’ll focus on C++ and try to:
highlight what needs attention (what C++’s problem “is”), and how we can get there by building on solutions already underway;
address some common misconceptions (what C++’s problem “isn’t”), including practical considerations of MSLs; and
leave a call to action for programmers using all languages.
tl;dr: I don’t want C++ to limit what I can express efficiently. I just want C++ to let me enforce our already-well-known safety rules and best practices by default, and make me opt out explicitly if that’s what I want. Then I can still use fully modern C++… just nicer.
Let’s dig in.
The immediate problem “is” that it’s Too Easy By Default™ to write security and safety vulnerabilities in C++ that would have been caught by stricter enforcement of known rules for type, bounds, initialization, and lifetime language safety
In C++, we need to start with improving these four categories. These are the main four sources of improvement provided by all the MSLs that NIST/NSA/CISA/etc. recommend using instead of C++ (example), so by definition addressing these four would address the immediate NIST/NSA/CISA/etc. issues with C++. (More on this under “The problem ‘isn’t’… (1)” below.)
And in all recent years including 2023 (see figures 1’s four highlighted rows, and figure 2), these four constitute the bulk of those oft-quoted 70% of CVEs (Common [Security] Vulnerabilities and Exposures) related to language memory unsafety. (However, that “70% of language memory unsafety CVEs” is misleading; for example, in figure 1, most of MITRE’s 2023 “most dangerous weaknesses” did not involve language safety and so are outside that denominator. More on this under “The problem ‘isn’t’… (3)” below.)
The C++ guidance literature already broadly agrees on safety rules in those categories. It’s true that there is some conflicting guidance literature, particularly in environments that ban exceptions or run-time type support and so use some alternative rules. But there is consensus on core safety rules, such as banning unsafe casts, uninitialized variables, and out-of-bounds accesses (see Appendix).
C++ should provide a way to enforce them by default, and require explicit opt-out where needed. We can and do write “good” code and secure applications in C++. But it’s easy even for experienced C++ developers to accidentally write “bad” code and security vulnerabilities that C++ silently accepts, and that would be rejected as safety violations in other languages. We need the standard language to help more by enforcing the known best practices, rather than relying on additional nonstandard tools to recommend them.
These are not the only four aspects of language safety we should address. They are just the immediate ones, a set of clear low-hanging fruit where there is both a clear need and clear way to improve (see Appendix).
Note: And safety categories are of course interrelated. For example, full type safety (that an accessed object is a valid object of its type) requires eliminating out-of-bounds accesses to unallocated objects. But, conversely, full bounds safety (that accessed memory is inside allocated bounds) similarly requires eliminating type-unsafe downcasts to larger derived-type objects that would appear to extend beyond the actual allocation.
Software safety is also important. Cyberattacks are urgent, so it’s natural that recent discussions have focused more on security and CVEs first. But as we specify and evolve default language safety rules, we must also include our stakeholders who care deeply about functional safety issues that are not reflected in the major CVE buckets but are just as harmful to life and property when left in code. Programming language safety helps both software security and software safety, and we should start somewhere, so let’s start (but not end) with the known pain points of security CVEs.
In those four buckets, a 10-50x improvement (90-98% reduction) is sufficient
If there were 90-98% fewer C++ type/bounds/initialization/lifetime vulnerabilities we wouldn’t be having this discussion. All languages have CVEs, C++ just has more (and C still more). [Updated: Removed count of 2024 Rust vs C/C++ CVEs because MITRE.org search doesn’t have a great way of accurately counting the latter.] So zero isn’t the goal; something like a 90% reduction is necessary, and a 98% reduction is sufficient, to achieve security parity with the levels of language safety provided by MSLs… and has the strong benefit that I believe it can be achieved with perfect backward link compatibility (i.e., without changing C++’s object model, and its lifetime model which does not depend on universal tracing garbage collection and is not limited to tree-based data structures) which is essential to our being able to adopt the improvements in existing C++ projects as easily as we can adopt other new editions of C++. — After that, we can pursue additional improvements to other buckets, such as thread safety and overflow safety.
Aiming for 100%, or zero CVEs in those four buckets, would be a mistake:
100% is not necessary because none of the MSLs we’re being told to use instead are there either. More on this in “The problem ‘isn’t’… (2)” below.
100% is not sufficient because many cyberattacks exploit security weaknesses other than memory safety.
And getting that last 2% would be too costly, because it would require giving up on link compatibility and seamless interoperability (or “interop”) with today’s C++ code. For example, Rust’s object model and borrow checker deliver great guarantees, but require fundamental incompatibility with C++ and so make interop hard beyond the usual C interop level. One reason is that Rust’s safe language pointers are limited to expressing tree-shaped data structures that have no cycles; that unique ownership is essential to having great language-enforced aliasing guarantees, but it also requires programmers to use ‘something else’ for anything more complex than a tree (e.g., using Rc, or using integer indexes as ersatz pointers); it’s not just about linked lists but those are a simple well-known illustrative example.
If we can get a 98% improvement and still have fully compatible interop with existing C++, that would be a holy grail worth serious investment.
A 98% reduction across those four categories is achievable in new/updated C++ code, and partially in existing code
Since at least 2014, Bjarne Stroustrup has advocated addressing safety in C++ via a “subset of a superset”: That is, first “superset” to add essential items not available in C++14, then “subset” to exclude the unsafe constructs that now all have replacements.
As of C++20, I believe we have achieved the “superset,” notably by standardizing span, string_view, concepts, and bounds-aware ranges. We may still want a handful more features, such as a null-terminated zstring_view, but the major additions already exist.
Now we should “subset”: Enable C++ programmers to enforce best practices around type and memory safety, by default, in new code and code they can update to conform to the subset. Enabling safety rules by default would not limit the language’s power but would require explicit opt-outs for non-standard practices, thereby reducing inadvertent risks. And it could be evolved over time, which is important because C++ is a living language and adversaries will keep changing their attacks.
ISO C++ evolution is already pursuing Safety Profiles for C++. The suggestions in the Appendix are refinements to that, to demonstrate specific enforcements and to try to maximize their adoptability and useful impact. For example, everyone agrees that many safety bugs will require code changes to fix. However, how many safety bugs could be fixed without manual source code changes, so that just recompiling existing code with safety profiles enabled delivers some safety benefits? For example, we could by default inject a call-site bounds check 0 <= b < a.size() on every subscript expression a[b] when a.size() exists and a is a contiguous container, without requiring any source code changes and without upgrading to a new internally bounds-checked container library; that checking would Just Work out of the box with every contiguous C++ standard container, span, string_view, and third-party custom container with no library updates needed (including therefore also no concern about ABI breakage).
Rules like those summarized in the Appendix would have prevented (at compile time, test time or run time) most of the past CVEs I’ve reviewed in the type, bounds, and initialization categories, and would have prevented many of the lifetime CVEs. I estimate a roughly 98% reduction in those categories is achievable in a well-defined and standardized way for C++ to enable safety rules by default, while still retaining perfect backward link compatibility. See the Appendix for a more detailed description.
We can and should emphasize adoptability and benefit also for C++ code that cannot easily be changed. Any code change to conform to safety rules carries a cost; worse, not all code can be easily updated to conform to safety rules (e.g., it’s old and not understood, it belongs to a third party that won’t allow updates, it belongs to a shared project that won’t take upstream changes and can’t easily be forked). That’s why above (and in the Appendix) I stress that C++ should seriously try to deliver as many of the safety improvements as practical without requiring manual source code changes, notably by automatically making existing code do the right thing when that is clear (e.g., the bounds checks mentioned above, or emitting static_cast pointer downcasts as effectively dynamic_cast without requiring the code to be changed), and by offering automated fixits that the programmer can choose to apply (e.g., to change the source for static_cast pointer downcasts to actually say dynamic_cast). Even though in many cases a programmer will need to thoughtfully update code to replace inherently unsafe constructs that can’t be automatically fixed, I believe for some percentage of cases we can deliver safety improvements by just recompiling existing code in the safety-rules-by-default mode, and we should try because it’s essential to maximizing safety profiles’ adoptability and impact.
What the problem “isn’t”: Some common misconceptions
(1) The problem “isn’t” defining what we mean by “C++’s most urgent language safety problem.” We know the four kinds of safety that most urgently need to be improved: type, bounds, initialization, and lifetime safety.
We know these four are the low-hanging fruit (see “The problem ‘is’…” above). It’s true that these are just four of perhaps two dozen kinds of “safety” categories, including ones like safe integer arithmetic. But:
Most of the others are either much smaller sources of problems, or are primarily important because they contribute to those four main categories. For example, the integer overflows we care most about are indexes and sizes, which fall under bounds safety.
Most MSLs don’t address making these safe by default either, typically due to the checking cost. But all languages (including C++) usually have libraries and tools to address them. For example, Microsoft ships a SafeInt library for C++ to handle integer overflows, which is opt-in. C# has a checked arithmetic language feature to handle integer overflows, which is opt-in. Python’s built-in integers are overflow-safe by default because they automatically expand; however, the popular NumPy fixed-size integer types do not check for overflow by default and require using checked functions, which is opt-in.
Thread safety is obviously important too, and I’m not ignoring it. I’m just pointing out that it is not one of the top target buckets: Most of the MSLs that NIST/NSA/CISA/etc. recommend over C++ (except uniquely Rust, and to a lesser extent Python) address thread safety impact on userdata corruption about as well as C++. The main improvement MSLs give is that a program data race will not corrupt the language’s own virtual machine (whereas in C++ a data race is currently all-bets-are-off undefined behavior). Some languages do give some additional protection, such as that Python guarantees two racing threads cannot see a torn write of an integer and reduces other possible interleavings because of the global interpreter lock (GIL).
(2) The problem “isn’t” that C++ code is not formally provably safe.
Yes, C++ code makes it too easy to write silently-unsafe code by default (see “The problem ‘is’…” above).
But I’ve seen some people claim we need to require languages to be formally provably safe, and that would be a bridge too far. Much to the chagrin of CS theorists, mainstream commercial programming languages aren’t formally provably safe. Consider some examples:
None of the widely-used languages we view as MSLs (except uniquely Rust) claim to be thread-safe and race-free by construction, as covered in the previous section. Yet we still call C#, Go, Java, Python, and similar languages “safe.” Therefore, formally guaranteeing thread safety properties can’t be a requirement to be considered a sufficiently safe language.
That’s because a language’s choice of safety guarantees is a tradeoff: For example, in Rust, safe code uses tree-based dynamic data structures only. This feature lets Rust deliver stronger thread safety guarantees than other safe languages, because it can more easily reason about and control aliasing. However, this same feature also requires Rust programs to use unsafe code more often to represent common data structures that do not require unsafe code to represent in other MSLs such as C# or Java, and so 30% to 50% of Rust crates use unsafe code, compared for example to 25% of Java libraries.
C#, Java, and other MSLs still have use-before-initialized and use-after-destroyed type safety problems too: They guarantee not accessing memory outside its allocated lifetime, but object lifetime is a subset of memory lifetime (objects are constructed after, and destroyed/disposed before, the raw memory is allocated and deallocated; before construction and after dispose, the memory is allocated but contains “raw bits” that likely don’t represent a valid object of its type). If you doubt, please run (don’t walk) and ask ChatGPT about Java and C# problems with: access-unconstructed-object bugs (e.g., in those languages, any virtual call in a constructor is “deep” and executes in a derived object before the derived object’s state is initialized); use-after-dispose bugs; “resurrection” bugs; and why those languages tell people never to use their finalizers. Yet these are great languages and we rightly consider them safe languages. Therefore, formally guaranteeing no-use-before-initialized and no-use-after-dispose can’t be a requirement to be considered a sufficiently safe language.
Rust, Go, and other languages support sanitizers too, including ThreadSanitizer and undefined behavior sanitizers, and related tools like fuzzers. Sanitizers are known to be still needed as a complement to language safety, and not only for when programmers use ‘unsafe’ code; furthermore, they go beyond finding memory safety issues. The uses of Rust at scale that I know of also enforce use of sanitizers. So using sanitizers can’t be an indicator that a language is unsafe — we should use the supported sanitizers for code written in any language.
Note: “Use your sanitizers” does not mean to use all of them all the time. Some sanitizers conflict with each other, so you can only use those one at a time. Some sanitizers are expensive, so they should only be run periodically. Some sanitizers should not be run in production, including because their presence can create new security vulnerabilities.
(3) The problem “isn’t” that moving the world’s C and C++ code to memory-safe languages (MSLs) would eliminate 70% of security vulnerabilities.
MSLs are wonderful! They just aren’t a silver bullet.
An oft-quoted number is that “70%” of programming language-caused CVEs (reported security vulnerabilities) in C and C++ code are due to language safety problems. That number is true and repeatable, but has been badly misinterpreted in the press: No security expert I know believes that if we could wave a magic wand and instantly transform all the world’s code to MSLs, that we’d have 70% fewer CVEs, data breaches, and ransomware attacks. (For example, see this February 2024 example analysis paper.)
Consider some reasons.
That 70% is of the subset of security CVEs that can be addressed by programming language safety. See figure 1 again: Most of 2023’s top 10 “most dangerous software weaknesses” were not related to memory safety. Many of 2023’s largest data breaches and other cyberattacks and cybercrime had nothing to do with programming languages at all. In 2023, attackers reduced their use of malware because software is getting hardened and endpoint protection is effective (CRN), and attackers go after the slowest animal in the herd. Most of the issues listed in NISTIR-8397 affect all languages equally, as they go beyond memory safety (e.g., Log4j) or even programming languages (e.g., automated testing, hardcoded secrets, enabling OS protections, string/SQL injections, software bills of materials). For more detail see the Microsoft response to NISTIR-8397, for which I was the editor. (More on this in the Call to Action.)
MSLs get CVEs too, though definitely fewer (again, e.g., Log4j). For example, see MITRE list of Rust CVEs, including six so far in 2024. And all programs use unsafe code; for example, see the Conclusions section of Firouzi et al.’s study of uses of C#’s unsafe on StackOverflow and prevalence of vulnerabilities, and that all programs eventually call trusted native libraries or operating system code.
Saying the quiet part out loud: CVEs are known to be an imprecise metric. We use it because it’s the metric we have, at least for security vulnerabilities, but we should use it with care. This may surprise you, as it did me, because we hear a lot about CVEs. But whenever I’ve suggested improvements for C++ and measuring “success” via a reduction in CVEs (including in this essay), security experts insist to me that CVEs aren’t a great metric to use… including the same experts who had previously quoted the 70% CVE number to me. — Reasons why CVEs aren’t a great metric include that CVEs are self-reported and often self-selected, and not all are equally exploitable; but there can be pressure to report a bug as a vulnerability even if there’s no reasonable exploit because of the benefits of getting one’s name on a CVE. In August 2023, the Python Software Foundation became a CVE Numbering Authority (CNA) for Python and pip distributions, and now has more control over Python and pip CVEs. The C++ community has not done so.
CVEs target only software security vulnerabilities (cyberattacks and intrusions), and we also need to consider software safety (life-critical systems and unintended harm to humans).
(4) The problem “isn’t” that C++ programmers aren’t trying hard enough / using the existing tools well enough. The challenge is making it easier to enable them.
Today, the mitigations and tools we do have for C++ code are an uneven mix, and all are off-by-default:
Kind. They are a mix of static tools, dynamic tools, compiler switches, libraries, and language features.
Acquisition. They are acquired in a mix of ways: in-the-box in the C++ compiler, optional downloads, third-party products, and some you need to google around to discover.
Accuracy. Existing rulesets mix rules with low and high false positives. The latter are effectively unadoptable by programmers, and their presence makes it difficult to “just adopt this whole set of rules.”
Determinism. Some rules, such as ones that rely on interprocedural analysis of full call trees, are inherently nondeterministic (because an implementation gives up when fully evaluating a case exceeds the space and time available; a.k.a. “best effort” analysis). This means that two implementations of the identical rule can give different answers for identical code (and therefore nondeterministic rules are also not portable, see below).
Efficiency. Existing rulesets mix rules with low and high (and sometimes impossible) cost to diagnose. The rules that are not efficient enough to implement in the compiler will always be relegated to optional standalone tools.
Portability. Not all rules are supported by all vendors. “Conforms to ISO/IEC 14882 (Standard C++)” is the only thing every C++ tool vendor supports portably.
To address all these points, I think we need the C++ standard to specify a mode of well-agreed and low-or-zero-false-positive deterministic rules that are sufficiently low-cost to implement in-the-box at build time.
Call(s) to action
As an industry generally, we must make a major improvement in programming language memory safety — and we will.
In C++ specifically, we should first target the four key safety categories that are our perennial empirical attack points (type, bounds, initialization, and lifetime safety), and drive vulnerabilities in these four areas down to the noise for new/updated C++ code — and we can.
But we must also recognize that programming language safety is not a silver bullet to achieve cybersecurity and software safety. It’s one battle (not even the biggest) in a long war: Whenever we harden one part of our systems and make that more expensive to attack, attackers always switch to the next slowest animal in the herd. Many of 2023’s worst data breaches did not involve malware, but were caused by inadequately stored credentials (e.g., Kubernetes Secrets on public GitHub repos), misconfigured servers (e.g., DarkBeam, Kid Security), lack of testing, supply chain vulnerabilities, social engineering, and other problems that are independent of programming languages. Apple’s white paper about 2023’s rise in cybercrime emphasizes improving the handling, not of program code, but of the data: “it’s imperative that organizations consider limiting the amount of personal data they store in readable format while making a greater effort to protect the sensitive consumer data that they do store [including by using] end-to-end [E2E] encryption.”
No matter what programming language we use, security hygiene is essential:
Do use your language’s static analyzers and sanitizers. Never pretend using static analyzers and sanitizers is unnecessary “because I’m using a safe language.” If you’re using C++, Go, or Rust, then use those languages’ supported analyzers and sanitizers. If you’re a manager, don’t allow your product to be shipped without using these tools. (Again: This doesn’t mean running all sanitizers all the time; some sanitizers conflict and so can’t be used at the same time, some are expensive and so should be used periodically, and some should be run only in testing and never in production including because their presence can create new security vulnerabilities.)
Do keep all your tools updated. Regular patching is not just for iOS and Windows, but also for your compilers, libraries, and IDEs.
Do secure your software supply chain. Do use package management for library dependencies. Do track a software bill of materials for your projects.
Don’t store secrets in code. (Or, for goodness’ sake, on GitHub!)
Do configure your servers correctly, especially public Internet-facing ones. (Turn authentication on! Change the default password!)
Do keep non-public data encrypted, both when at rest (on disk) and when in motion (ideally E2E… and oppose proposed legislation that tries to neuter E2E encryption with ‘backdoors only good guys will use’ because there’s no such thing).
Do keep investing long-term in keeping your threat modeling current, so that you can stay adaptive as your adversaries keep trying different attack methods.
We need to improve software security and software safety across the industry, especially by improving programming language safety in C and C++, and in C++ a 98% improvement in the four most common problem areas is achievable in the medium term. But if we focus on programming language safety alone, we may find ourselves fighting yesterday’s war and missing larger past and future security dangers that affect software written in any language.
Sadly, there are too many bad actors. For the foreseeable future, our software and data will continue to be under attack, written in any language and stored anywhere. But we can defend our programs and systems, and we will.
Be well, and may we all keep working to have a safer and more secure 2024.
Appendix: Illustrating why a 98% reduction is feasible
This Appendix exists to support why I think a 98% reduction in type/bounds/initialization/lifetime CVEs in C++ code is believable. This is not a formal proposal, but an overview of concrete ways to achieve such an improvement it in new and updatable code, and ways to even get some fraction of that improvement in existing code we cannot update but can recompile. These notes are aligned with the proposals currently being pursued in the ISO C++ safety subgroup, and if they pan out as I expect in ongoing discussions and experiments, then I intend to write further details about them in a future paper.
There are runtime and code size overheads to some of the suggestions in all four buckets, notably checking bounds and casts. But there is no reason to think those overheads need to be inherently worse in C++ than other languages, and we can make them on by default and still provide a way to opt out to regain full performance where needed.
Note: For example, bounds checking can cause a major impact on some hot loops, when using a compiler whose optimizer does not hoist bounds checks; not only can the loops incur redundant checking, but they also may not get other optimizations such as not being vectorized. This is why making bounds-checking on by default is good, but all performance-oriented languages also need to provide a way to say “trust me” and explicitly opt out of bounds checking tactically where needed.
The best way for “how” to let the programmer control enabling those rules (e.g., via source code annotations, compiler switches, and/or something else) is an orthogonal UX issue that is now being actively discussed in the C++ standards committee and community.
Type safety
Enforce the Pro.Type safety profile by default. That includes either banning or checking all unsafe casts and conversions (e.g., static_cast pointer downcasts, reinterpret_cast), including implicit unsafe type punning via C union and vararg.
However, these rules haven’t yet been systematically enforced in the industry. For example, in recent years I’ve painfully observed a significant set of type safety-caused security vulnerabilities whose root cause was that code used static_cast instead of dynamic_cast for pointer downcasts, and “C++” gets blamed even when the actual problem was failure to follow the well-publicized guidance to use the language’s existing safe recommended feature. It’s time for a standardized C++ mode that enforces these rules by default.
Note: On some platforms and for some applications, dynamic_cast has problematic space and time overheads that hinder its use. Many implementations bundle dynamic_cast indivisibly with all C++ run-time typing (RTTI) features (e.g., typeid), and so require storing full potentially-heavyweight RTTI data even though dynamic_cast needs only a small subset. Some implementations also use needlessly inefficient algorithms for dynamic_cast itself. So the standard must encourage (and, if possible, enforce for conformance, such as by setting algorithmic complexity requirements) that dynamic_cast implementations be more efficient and decoupled from other RTTI overheads, so that programmers do not have a legitimate performance reason not to use the safe feature. That decoupling could require an ABI break; if that is unacceptable, the standard must provide an alternative lightweight facility such as a fast_dynamic_cast that is separate from (other) RTTI and performs the dynamic cast with minimum space and time cost.
Bounds safety
Enforce the Pro.Bounds safety profile by default, and guarantee bounds checking. We should additionally guarantee that:
Pointer arithmetic is banned (use std::span instead); this enforces that a pointer refers to a single object. Array-to-pointer decay, if allowed, will point to only the first object in the array.
Only bounds-checked iterator arithmetic is allowed (also, prefer ranges instead).
All subscript operations are bounds-checked at the call site, by having the compiler inject an automatic subscript bounds check on every expression of the form a[b], where a is a contiguous sequence with a size/ssize function and b is an integral index. When a violation happens, the action taken can be customized using a global bounds violation handler; some programs will want to terminate (the default), others will want to log-and-continue, throw an exception, integrate with a project-specific critical fault infrastructure.
Importantly, the latter explicitly avoids implementing bounds-checking intrusively for each individual container/range/view type. Implementing bounds-checking non-intrusively and automatically at the call site makes full bounds checking available for every existing standard and user-written container/range/view type out of the box: Every subscript into a vector, span, deque, or similar existing type in third-party and company-internal libraries would be usable in checked mode without any need for a library upgrade.
It’s important to add automatic call-site checking now before libraries continue adding more subscript bounds checking in each library, so that we avoid duplicating checks at the call site and in the callee. As a counterexample, C# took many years to get rid of duplicate caller-and-callee checking, but succeeded and .NET Core addresses this better now; we can avoid most of that duplicate-check-elimination optimization work by offering automatic call-site checking sooner.
Language constructs like the range-for loop are already safe by construction and need no checks.
In cases where bounds checking incurs a performance impact, code can still explicitly opt out of the bounds check in just those paths to retain full performance and still have full bounds checking in the rest of the application.
Initialization safety
Enforce initialization-before-use by default. That’s pretty easy to statically guarantee, except for some cases of the unused parts of lazily constructed array/vector storage. Two simple alternatives we could enforce are (either is sufficient):
Initialize-at-declaration as required by Pro.Type and ES.20; and possibly zero-initialize data by default as currently proposed in P2723. These two are good but with some drawbacks; both have some performance costs for cases that require ‘dummy’ writes that are never used but hard for optimizers to eliminate, and the latter has some correctness costs because it ‘fixing’ some uninitialized cases where zero is a valid value but masks others for which zero is not a valid initializer and so the behavior is still wrong, but because a zero has been jammed in it’s harder for sanitizers to detect.
Guaranteed initialization-before-use, similar to what Ada and C# successfully do. This is still simple to use, but can be more efficient because it avoids the need for artificial ‘dummy’ writes, and can be more flexible because it allows alternative constructors to be used for the same object on different paths. For details, see: example diagnostic; definite-first-use rules.
Lifetime safety
Enforce the Pro.Lifetime safety profile by default, ban manual allocation by default, and guarantee null checking. The Lifetime profile is a static analysis that diagnoses many common sources of dangling and use-after-free, including for iterators and views (not just raw pointers and references), in a way that is efficient enough to run during compilation. It can be used as a basis to iterate on and further improve. And we should additionally guarantee that:
All manual memory management is banned by default (new, delete, malloc, and free). Corollary: ‘Owning’ raw pointers are banned by default, since they require delete or free. Use RAII instead, such as by calling make_unique or make_shared.
All dereferences are null-checked. The compiler injects an automatic check on every expression of the form *p or p-> where p can be compared to nullptr to null-check all dereferences at the call site (similar to bounds checks above). When a violation happens, the action taken can be customized using a global null violation handler; some programs will want to terminate (the default), others will want to log-and-continue, throw an exception, integrate with a project-specific critical fault infrastructure.
Note: The compiler could choose to not emit this check (and not perform optimizations that benefit from the check) when targeting platforms that already trap null dereferences, such as platforms that mark low memory pages as unaddressable. Some C++ features, such as delete, have always done call-site null checking.
Reducing undefined behavior and semantic bugs
Tactically, reduce some undefined behavior (UB) and other semantic bugs (pitfalls), for cases where we can automatically diagnose or even fix well-known antipatterns. Not all UB is bad; any performance-oriented language needs some. But we know there is low-hanging fruit where the programmer’s intent is clear and any UB or pitfall is a definite bug, so we can do one of two things:
(A – Good) Make the pitfall a diagnosed error, with zero false positives — every violation is a real bug. Two examples mentioned above are to automatically check a[b] to be in bounds and *p and p-> to be non-null.
(B – Ideal) Make the code actually do what the programmer intended, with zero false positives — i.e., fix it by just recompiling. An example, discussed at the most recent ISO C++ November 2023 meeting, is to default to an implicit return *this; when the programmer writes an assignment operator for their type C that returns a C& (note: the same type), but forgets to write a return statement. Today, that is undefined behavior. Yet it’s clear that the programmer meant return *this; — nothing else can be valid. If we make return *this; be the default, all the existing code that accidentally omits the return is not just “no longer UB,” but is guaranteed to do the right and intended thing.
An example of both (A) and (B) is to support chained comparisons, that makes the mathematically valid chains work correctly and rejects the mathematically invalid ones at compile time. Real-world code does write such chains by accident (see: [a][b][c][d][e][f][g][h][i][j][k]).
For (A): We can reject all mathematically invalid chains like a != b > c at compile time. This automatically diagnoses bugs in existing code that tries to do such nonsense chains, with perfect accuracy.
For (B): We can fix all existing code that writes would-be-correct chains like 0 <= index < max. Today those silently compile but are completely wrong, and we can make them mean the right thing. This automatically fixes those bugs, just by recompiling the existing code.
These examples are not exhaustive. We should review the list of UB in the standard for a more thorough list of cases we can automatically fix (ideally) or diagnose.
Summarizing: Better defaults for C++
C++ could enable turning safety rules on by default that would make code:
fully type-safe,
fully bounds-safe,
fully initialization-safe,
and for lifetime safety, which is the hardest of the four, and where I would expect the remaining vulnerabilities in these categories would mostly lie:
fully null-safe,
fully free of owning raw pointers,
with lifetime-safety static analysis that diagnoses most common pointer/iterator/view lifetime errors;
and, finally:
with less undefined behavior including by automatically fixing existing bugs just by recompiling code with safety enabled by default.
All of this is efficiently implementable and has been implemented. Most of the Lifetime rules have been implemented in Visual Studio and CLion, and I’m prototyping a proof-of-concept mode of C++ that includes all of the other above language safeties on-by-default in my cppfront compiler, as well as other safety improvements including an implementation of the current proposal for ISO C++ contracts. I haven’t yet used the prototype at scale. However, I can report that the first major change request I received from early users was to change the bounds checking and null checking from opt-in (off by default) to opt-out (on by default).
Note: Please don’t be distracted by that cppfront uses an experimental alternate syntax for C++. That’s because I’m additionally trying to see if we can reach a second orthogonal goal: to make the C++ language itself simpler, and eliminate the need to teach ~90% of the C++ guidance literature related to language complexity and quirks. This essay’s language safety improvements are orthogonal to that, however, and can be applied equally to today’s C++ syntax.
Solutions need to distinguish between (A) “solution for new-or-updatable code” and (B) “solution for existing code.”
(A) A “solution for new-or-updatable code” means that to help existing code we have to change/rewrite our code. This includes not only “(re)write in C#/Rust/Go/Python/…,” but also “annotate your code with SAL” or “change your code to use std::span.”
One of the costs of (A) is that anytime we write/change code to fix bugs, we also introduce new bugs; change is never free. We need to recognize that changing our code to use std::span often means non-trivially rewriting parts of it which can also create other bugs. Even annotating our code means writing annotations that can have bugs (this is a common experience in the annotation languages I’ve seen used at scale, such as SAL). All these are significant adoption barriers.
Actually switching to another language means losing a mature ecosystem. C++ is the well-trod path: It’s taught, people know it, the tools exist, interop works, and current regulations have an industry around C++ (such as for functional safety). It takes another decade at least for another language to become the well-trod path, whereas a better C++, and its benefits to the industry broadly, can be here much sooner.
(B) A “solution for existing code” emphasizes the adoptability benefits of not having to make manual code changes. It includes anything that makes existing code more secure with “just a recompile” (i.e., no binary/ABI/link issues; e.g., ASAN, compiler switches to enable stack checks, static analysis that produces only true positives, or a reliable automated code modernizer).
We will still need (B) no matter how successful new languages or new C++ types/annotations are. And (B) has the strong benefit that it is easier to adopt. Getting to a 98% reduction in CVEs will require both (A) and (B), but if we can deliver even a 30% reduction using just (B) that will be a major benefit for adoption and effective impact in large existing code bases that are hard to change.
Consider how the ideas earlier in this appendix map onto (A) and (B):
In C++, by default enforce …
(A) Solution for new/updated code (can require code changes — no link/binary changes)
(B) Solution for existing code (requires recompile only — no manual code changes, no link/binary changes)
Type safety
Ban all inherently unsafe casts and conversions
Make unsafe casts and conversions with a safe alternative do the safe thing
Bounds safety
Ban pointer arithmetic Ban unchecked iterator arithmetic
Check in-bounds for all allowed iterator arithmetic Check in-bounds for all subscript operations
Initialization safety
Require all variables to be initialized (either at declaration, or before first use)
—
Lifetime safety
Statically diagnose many common pointer/iterator lifetime error cases
Check not-null for all pointer dereferences
Less undefined behavior
Statically diagnose known UB/bug cases, to error on actual bugs in existing code with just a recompile and zero false positives: Ban mathematically invalid comparison chains (add additional cases from UB Annex review)
Automatically fix known UB/bug cases, to make current bugs in existing code be actually correct with just a recompile and zero false positives: Define mathematically valid comparison chains Default return *this; for C assignment operators that return C& (add additional cases from UB Annex review)
By prioritizing adoptability, we can get at least some of the safety benefits just by recompiling existing code, and make the total improvement easier to deploy even when code updates are required. I think that makes it a valuable strategy to pursue.
Finally, please see again the main post’s conclusion: Call(s) to action.
I generally give one or two courses a year on C++ and related technologies. This year, on April 22-25, I’ll be giving a live online public course for four half-days, on the topic of high-performance low-latency coding in C++ — and the early registration discount is available for a few more days until this Thursday:
High performance and low latency code, via concurrency and parallelism
22-25th April 2024, from 14:00 – 18:00 CEST daily
Participants in this intensive course will acquire the knowledge and skills required to write high-performance and low-latency code on today’s modern systems using modern C++. Presented by Alfasoft.
See the course link for details and a syllabus of topics that will be covered.
The times are intended to be friendly to the home time zones of attendees anywhere in EMEA and also to early risers in the Americas. If you live in a part of the world where these times can’t work for you, and you’d like another offering of the course that is friendlier to your home time zone, please email Alfasoft to let them know!
Because “high-performance low-latency” is kind of C++’s bailiwick, and because it’s my course, you’ll be unsurprised to learn that the topics and code focus on C++ and include coverage of modern C++17/20/23 features. But we are polyglots, after all… so don’t be overly shocked that I may sometimes show a few code examples in other popular languages, if only for comparison and to show how the other half lives.
Today, the ISO C++ committee completed its second meeting of C++26, held in Kona, HI, USA.
Our hosts, Standard C++ Foundation and WorldQuant, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 170 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 21 nations. Also, at each meeting we regularly have new attendees who have never attended before, and this time there were over a dozen new first-time attendees, mostly in-person; to all of them, once again welcome!
The committee currently has 23 active subgroups, most of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their workloads. You can find a brief summary of ISO procedures here.
This week’s meeting: Meeting #2 of C++26
At the previous meeting in June, the committee adopted the first 40 proposed changes for C++26, including many that had been ready for a couple of meetings and were just waiting for the C++26 train to open to be adopted. For those highlights, see the previous trip report.
This time, the committee adopted the next set of features for C++26. It also made significant progress on other features that are now expected to be complete in time for C++26 — including contracts and reflection.
Here are some of the highlights…
Adopted for C++26: Core language changes/features
The core language adopted four papers, including P2662R3 “Pack indexing” by Corentin Jabot and Pablo Halpern officially adds support for using [idx] subscripting into variadic parameter packs. Here is an example from the paper that will now be legal:
For those interested in writing standards proposals, I would suggest looking at this and its two predecessors P1858 and P2632 as well written papers: The earlier papers delve into the motivating use cases, and this paper has a detailed treatment of other design alternatives considered and why this is the one chosen. Seeing only the end result of T...[0] would be easy to call “obvious” in hindsight, but it’s far from the only option and this paper’s analysis shows a thorough consideration of alternatives, including their effects on existing and future code and future language evolution.
Adopted for C++26: Standard library changes/features
The standard library adopted 19 papers, including the following…
The biggest, and probably this meeting’s award for “proposal being worked on the longest,” is P1673R13, “A free function linear algebra interface based on the BLAS” by Mark Hoemmen, Daisy Hollman, Christian Trott, Daniel Sunderland, Nevin Liber, Alicia Klinvex, Li-Ta Lo, Damien Lebrun-Grandie, Graham Lopez, Peter Caday, Sarah Knepper, Piotr Luszczek, and Timothy Costa, with the help of Bob Steagall, Guy Davidson, Andrew Lumsdaine, and Davis Herring. If you want to do efficient linear algebra, you don’t want to write your own code by hand; that would be slow. Instead, you want a library that is tuned for your target hardware architecture and ready for par_unseq vectorized algorithms, for blazing speed. This is that library. For detailed rationale, see in particular sections 5 “Why include dense linear algebra in the C++ Standard Library?” and 6 “Why base a C++ linear algebra library on the BLAS?”
P2905R2 “Runtime format strings” and P2918R2 “Runtime format strings II” by Victor Zverovich builds on the C++20 format library, which already supported compile-time format strings. Now with this pair of papers, we will have direct support for format strings not known at compile time and be able to opt out of compile-time format string checks.
P2546R5 “Debugging support” by René Ferdinand Rivera Morell, building on prior work by Isabella Muerte in P1279, adds std::breakpoint(), std::breakpoint_if_debugging(), and std::is_debugger_present(). This standardizes prior art already available in environments from Amazon Web Services to Unreal Engine and more, under a common standard API that gives the programmer full runtime control over breakpoints, including (quoting from the paper):
“allowing printing out extra output to help diagnose problems,
executing extra test code,
displaying an extra user interface to help in debugging, …
… breaking when an infrequent non-critical condition is detected,
allowing programmatic control with complex runtime sensitive conditions,
breaking on user input to inspect context in interactive programs without needing to switch to the debugger application,
and more.”
I can immediately think of times I would have used this in the past month, and probably you can too.
Those are some of the “bigger” papers as highlights… there were 16 papers other adopted too, including more extensions and fixes for the C++26 language and standard library.
On track for targeting C++26: Contracts
The contracts subgroup, SG21, decided several long-open questions that needed to be answered to land contracts in C++26. Perhaps not the most important one, but the one that’s the most visible, is the contracts syntax: This week, SG21 approved pursuing P2961R2 “A natural syntax for contracts” by Jens Maurer and Timur Doumler as the syntax for C++26 contracts. The major visible change is that instead of writing contracts like this:
// previous draft syntax
int f(int i)
[[pre: i >= 0]]
[[post r: r > 0]]
{
[[assert: i >= 0]]
return i+1;
}
we’ll write them like this, changing “assert” to “contract_assert”… pretty much everyone would prefer “assert,” if only it were backward-compatible, but in this new syntax it would hit an incompatibility with the C assert macro:
// newly adopted syntax
int f(int i)
pre (i >= 0)
post (r: r > 0)
{
contract_assert (i >= 0);
return i+1;
}
I already had a contracts implementation in my cppfront compiler, which used the previous [[]] syntax (because, when I have nothing clearly better, I try to follow syntax in existing/proposed C++). So, once P2961 was approved in the subgroup on Tuesday morning, I decided to take Tuesday afternoon to implement the change to this syntax, except that I kept the nice word “assert” because I can do that without a breaking change in my experimental alternate syntax. The work ended up taking not quite an hour, including to update the repo’s own code where I’m using contracts myself in the compiler and its unit tests. You can check out the diff in these | commits. My initial personal reaction, as an early contracts user, is that I like the result.
There are a handful of design questions still to decide, notably the semantics of implicit lambda capture, consteval, and multiple declarations. Six contracts telecons have been scheduled between now and the next meeting in March in Tokyo. The group is aiming to have a feature-complete proposal for Tokyo to forward to other groups for review.
Today when this progress was reported to the full committee, there was applause. As there should be, because this week’s progress increases the confidence that the feature is on track for C++26!
Note that “for C++26” doesn’t mean “that’s still three years away, maybe my kids can use it someday.” It means the feature has to be finished in just the next 18 months or so, and once it’s finished that unleashes implementations to be able to confidently go implement it. It’s quite possible we may see implementations available sooner, as we do with other popular in-demand draft standard features.
Speaking of major features that made great progress this meeting to be confidently on track for C++26…
The group then voted unanimously to adopt P2996R1 “Reflection for C++26” by Wyatt Childers, Peter Dimov, Barry Revzin, Andrew Sutton, Faisal Vali, and Daveed Vandevoorde and forward it on to the main Evolution and Library Evolution subgroups targeting C++26. This is a “core” of static reflection that is useful enough to solve many important problems, while letting us also plan to continue building on it further post-C++26.
This is particularly exciting for me personally, because we desperately need reflection in C++, and based on this week’s progress now is the first time I’ve felt confident enough to mention a target ship vehicle for this super important feature.
Perhaps the most common example of reflection is “enum to string”, so here’s that example:
template <typename E>
requires std::is_enum_v<E>
constexpr std::string enum_to_string(E value) {
template for (constexpr auto e : std::meta::members_of(^E)) {
if (value == [:e:]) {
return std::string(std::meta::name_of(e));
}
}
return "<unnamed>";
}
Note that the above uses some of the new reflection syntax, but this is just the implementation… the new syntax stays encapsulated there. The code that uses enum_to_string gets to not know anything about reflection, and just use the function:
enum Color { red, green, blue };
static_assert(enum_to_string(Color::red) == "red");
static_assert(enum_to_string(Color(42)) == "<unnamed>");
See the paper for much more detail, including more about enum-to-string in section 2.6.
Adding to the excitement, Edison Design Group noted that they expect to have an experimental implementation available on Godbolt Compiler Explorer by Christmas.
P2996 builds on the core of the original Reflection TS, and mainly changes the “top” and “bottom” layers that we knew we would likely change from the TS:
At the “top” or programming model layer, P2996 avoids having to do temp<late,meta<pro,gram>>::ming to use the API and lets us write something more like ordinary C++ code instead.
And at the “bottom” implementation layer, it uses a value-based implementation which is more efficient to implement.
This doesn’t mean the Reflection TS wasn’t useful; it was instrumental. Progress to this point would have been slower if we hadn’t been able to do the TS first, and we deeply appreciate all the work that went into that, as well as the new progress to move forward with P2996 as the reflection feature targeting C++26.
After the unanimous approval vote to forward this paper for C++26, there was a round of applause in the subgroup.
Then today, when this progress toward targeting C++26 was reported to the whole committee in the closing plenary session, the whole room was filled with sustained applause.
Other progress
Many other subgroups continued to make progress during the week. Here are a few highlights…
SG1 (Concurrency) will be working on out-of-thin-air issues for relaxed atomics at a face-to-face meeting or telecon between meetings. They are still on track to move forward with std::execution and SIMD parallelism for C++26, and SIMD was reviewed in the Library Evolution (LEWG) main subgroup; these features, in the words of the subgroup chair, will make C++26 a huge release for the concurrency and parallelism group.
SG4 (Networking) continued working on updating the networking proposal for std::execution senders and receivers. There is a lot of work still to be done and it is not clear on whether networking will be on track for C++26.
SG9 (Ranges) set a list of features and priorities for ranges for C++26. There are papers that need authors, including ones that would be good “first papers” for new authors, so please reach out to the Ranges chair, Daisy Hollman, if you are interested in contributing toward a Ranges paper.
SG15 (Tooling) considered papers on improving modules to enable better tooling, and work toward the first C++ Ecosystem standard.
SG23 (safety) subgroup made further progress towards safety profiles for C++ as proposed by Bjarne Stroustrup, and adopted it as the near-term direction for safety in C++. The updated paper will be available in the next mailing in mid-December.
Library Evolution (LEWG) started setting a framework for policies for new C++ libraries. The group also made progress on a number of proposals targeting C++26, including std::hive, SIMD (vector unit parallelism), ranges extensions, and std::execution, and possibly some support for physical units, all of which made good progress.
Language Evolution (EWG) worked on improving/forwarding/rejecting many proposals, including a set of discussions about improving undefined behavior in conjunction with the C committee, including eight papers about undefined behavior in the preprocessor. The group also decided to pursue doing a full audit of “ill-formed, no diagnostic required” undefined behavior that compilers currently are not required to detect and diagnose. The plan for our next meeting in Tokyo is to spend a lot of time on reflection, and prepare for focusing on contracts.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the over 170 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in just four months from now we’ll be meeting again in person + Zoom to continue adding features to C++26. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
Note: There’s already a Reddit thread for it, so if you want to comment on the video I suggest you use that thread instead of creating a new one.
At CppCon 2022, I argued for why we should try to make C++ 10x simpler and 50x safer, and this update is an evolution of the update talk I gave at C++ Now in May, with additional news and demos.
The “Dart plan” and the “TypeScript plan”
The back half of this talk clearly distinguishes between what I call the “Dart plan” and the “TypeScript plan” for aiming at a 10x improvement for an incumbent popular language. Both plans have value, but they have different priorities and therefore choose different constraints… most of all, they either embrace up-front the design constraint of perfect C++ interop and ecosystem compatibility, or they forgo it (forever; as I argue in the talk, it can never be achieved retroactively, except by starting over, because it’s a fundamental up-front constraint). No one else has tried the TypeScript plan for C++ yet, and I see value in trying it, and so that’s the plan I’m following for cppfront.
When people ask me “how is cppfront different from all the other projects trying to improve/replace C++?” my answer is “cppfront is on the TypeScript plan.” All the other past and present projects have been on the Dart plan, which again is a fine plan too, it just has different priorities and tradeoffs particularly around
full seamless interop compatibility with ISO Standard C++ code and libraries without any wrapping/thunking/marshaling,
full ecosystem compatibility with all of today’s C++ compilers, IDEs, build systems, and tooling, and
full standards evolution support with ISO C++, including not creating incompatible features (e.g., a different concepts feature than C++20’s, a different modules system than C++20’s) and bringing all major new pieces to today’s ISO C++ evolution as also incremental proposals for today’s C++.
See just the final 10 minutes of the talk to see what I mean — I demo’d syntax 2 “just working” with four different IDEs’ debuggers and visualizers, but I could also have demo’d that profilers just work, build systems just work, and so on.
I call my experimental syntax 2 (aka Cpp2) “still 100% pure C++” not only because cppfront translates it to 100% today’s C++ syntax (aka Cpp1), but because:
every syntax-2 type is an ordinary C++ type that ordinary existing C++ code can use, recognized by tools that know C++ types including IDE visualizers;
every syntax-2 function is an ordinary C++ function that ordinary existing C++ code can use, recognized by tools that know C++ functions including debuggers to step into them;
every syntax-2 object is an ordinary C++ object that ordinary existing C++ code can use;
every syntax-2 feature can be (and has been) brought as a normal ISO C++ standards proposal to evolve today’s syntax, because Cpp2 embraces and follows today’s C++ standard and guidance and evolution instead of competing with them;
and that’s because I want a way to keep writing 100% pure C++, just nicer.
“Nicer” means: 10x simpler by having more generality and consistency, better defaults, and less ceremony; and 50x safer by having 98% fewer vulnerabilities in the four areas of initialization safety (guaranteed in Cpp2), type safety (guaranteed in Cpp2), bounds safety (on by default in Cpp2), and lifetime safety (still to be implemented in cppfront is the C++ Core Guidelines Lifetime static analysis which I designed for Cpp2).
Cpp2 and cppfront don’t replace your C++ compilers. Cpp2 and cppfront work with all your existing C++ compilers (and build systems, profilers, debuggers, visualizers, custom in-house tools, test harnesses, and everything else in the established C++ ecosystem, from the big commercial public C++ products to your team’s internal bespoke C++ tools). If you’re already using GCC, Clang, and/or MSVC, keep using them, they all work fine. If you’re already using CMake or build2, or lldb or the Qt Creator debugger, or your favorite profiler or test framework, keep using them, it’s all still C++ that all C++ tools can understand. There’s no new ecosystem.
There are only two plans for 10x major improvement. (1-min clip) This is the fundamental difference with all the other attempts at a major improvement of today’s C++ I know of, which are all on the Dart plan — and those are great projects by really smart people and I hope we all learn from each other. But for my work I want to pursue the TypeScript plan, which I think is the only major evolution plan that can legitimately call itself “still 100% C++.” That’s important to me, because like I said at the very beginning of my talk last year (1-min clip), I want to encourage us to pursue major evolution that brings C++ itself forward and to double down on C++, not switch to something else — to aim for major C++ evolution directed to things that will make us better C++ programmers, not programmers of something else.
I’m spending time on this experiment first of all for myself, because C++ is the language that best lets me express the programs I need to write, so I want to keep writing real C++ types and real C++ functions and real C++ everything else… just nicer.
Thanks again to the over 120 people who have contributed issues and PRs to cppfront, and the many more who have provided thoughtful comments and feedback! I appreciate your help.
I’ll be giving a major update next week at CppCon. I hope to see many of you there! In the meantime, here are some notes about what’s been happening since the spring update post, including:
Acknowledgments and thanks
Started self-hosting
No data left behind: Mandatory explicit discard
requires clauses
Generalized aliases+constexpr with ==
Safe enum and flag_enum metafunctions
Safe union metafunction
What’s next
Acknowledgments: Thank you!
Thank you to all these folks who have participated in the cppfront repo by opening issues and PRs, and to many more who participated on PR reviews and comment threads! These contributors represent people from high school and undergrad students to full professors, from commercial developers to conference speakers, and from every continent except Antarctica.
Started self-hosting
I haven’t spent a lot of time yet converting cppfront’s own code from today’s syntax 1 to my alternate syntax 2 (which I’m calling “Cpp1” and “Cpp2” for short), but I started with all of cppfront’s reflection API and metafunctions which are now mostly written in Cpp2. Here’s what that reflect.h2 file compilation looks like when compiled on the command line on my laptop:
But note you can still build cppfront as all-today’s-C++ using any fairly recent C++20 compiler because I distribute the sources also as C++ (just as Bjarne distributed the cfront sources also as C).
No data left behind: Mandatory explicit discard
Initialization and data flow are fundamental to safe code, so from the outset I ensured that syntax 2 guaranteed initialization-before use, I made all converting constructors explicit by default… and I made [[nodiscard]] the default for return values (1-min talk clip).
The more I thought about [[nodiscard]], the more determined I was that data must never be silently lost, and data-lossy operations should be explicit. So I’ve decided to try an aggressive experiment:
make “nodiscard” the law of the land, implicitly required all the time, with no opt-out…
including when calling existing C++ libraries (including std::) that were never designed for their return values to be treated as [[nodiscard]]!
Now, I wasn’t totally crazy: See the Design note: Explicit discard for details on how I first surveyed other languages’ designers about experience in their languages — notably C#, F#, and Python. In particular, F# does the same thing with .NET APIs — F# requires explicit |> ignore to discard unused return values, including for .NET APIs that were never designed for that and were largely written in other languages. Don Syme told me it has not been a significant pain point, and that was encouraging, so I’m following suit.
My experience so far is that it’s pretty painless, and I write about one explicit discard for every 200 lines of code, even when using the C++ standard library (which cppfront does pervasively, because the C++ standard library is the only library cppfront uses). And, so far, every time cppfront told me I had to write an explicit discard, I learned something useful (e.g., before this I never realized that emplace_back started to return something since C++17! push_back still doesn’t) and I found I liked that my code explicitly self-documented it was not looking at output values… my code looked better.
The way to do an explicit discard is to assign the result to the “don’t care” wildcard. It’s unobtrusive, but explicit and clear:
_ = vec.emplace_back(1,2,3);
Now all Cpp2-authored C++ functions are emitted as [[nodiscard]], except only for assignment and streaming operators because those are designed for chaining and every chain always ends with a discarded return.
And the whole language hangs together well: Explicit discard works very naturally with inout and out parameters too, not just return values. If you have a local variable x and pass it to an inout parameter, what if that’s the last use of the variable?
{
x := my_vector.begin();
std::advance(x, 2);
// ERROR, if param is Cpp2 'inout' or Cpp1 non-const '&'
}
In this example, that call to std::advance(x, 2); is a definite last use of x, and so Cpp2 will automatically pass x as an rvalue and make it a move candidate… and presto! the call won’t compile because you can’t pass an rvalue to a Cpp2 inout parameter (the same as a Cpp1 non-const-& parameter, so this correctly detects the output side effects also when calling existing C++ functions that take references to non-const). That’s a feature, not a bug, because if that’s the last use of x that means the function is not looking at x again, so it’s ignoring the “out” value of the std::advance(x, 2) function call, which is exactly like ignoring a return value. And the guidance is the same: If you really meant to do that, just explicitly discard x‘s final value:
{
x := my_vector.begin();
std::advance(x, 2);
_ = x; // all right, you said you meant it, carry on then...
}
Adding _ = x; afterward naturally makes that the last use of x instead. Problem solved, and it self-documents that the code really meant to ignore a function’s output value.
I really, really like how my C++ code’s data flow is explicit, and fully protected and safe, in syntax 2. And I’m very pleased to see how it just works naturally throughout the language — from universal guaranteed initialization, to explicit constructors by default, to banning implicitly discarding any values, to uniform treatment of returned values whether returned by return value or the “out” part of inout and out parameters, and all of it working also with existing C++ libraries so they’re safer and nicer to use from syntax 2. Data is always initialized, data is never silently lost, data flow is always visible. Data is precious, and it’s always safe. This feels right and proper to me.
requires clauses
I also added support for requires clauses, so now you can write those on all templates. The cppfront implementation was already generating some requires clauses already (see this 1-min video clip). Now programmers can write their own too.
This required a bit of fighting with a GCC 10 bug about requires-clauses on declarations, that was fixed in GCC 11+ but was never backported. But because this was the only problem I’ve encountered with GCC 10 that I couldn’t paper over, and because I could give a clear diagnostic that a few features in Cpp2 that rely on requires clauses aren’t supported on GCC 10, so far I’ve been able to retain GCC 10 as a supported compiler and emit diagnostics if you try to use those few features it doesn’t support. GCC 11 and higher are all fine and support all Cpp2 semantics.
Generalized aliases+constexpr with ==
In the April blog post, I mentioned I needed a way to write type and namespace aliases, and that because all Cpp2 declarations are of the form thing : type = value, I decided to try using the same syntax but with == to denote “always equal to.”
// namespace alias
lit: namespace == ::std::literals;
// type alias
pmr_vec: <T> type
== std::vector<T, std::pmr::polymorphic_allocator<T>>;
I think this clearly denotes that lit is always the same as ::std::literals, and pmr_vec<int> is always the same as std::vector<int, std::pmr::polymorphic_allocator<int>>.
Since then, I’ve thought about how this should be best extended to functions and objects, and I realized the requirements seem to overlap with something else I needed to support: constexpr functions and objects. Which, after all, are functions/objects that return/have “always the same values” known at compile time…
// function with "always the same value" (constexpr function)
increment: (value: int) -> int == value+1;
// Cpp2 lets you omit { return } around 1-line bodies
// object with "always the same value" (constexpr object)
forty_two: i64 == 42;
I particularly needed these in order to write the enum metafunctions…
Safe enum and flag_enum metafunctions
In the spring update blog post, I described the first 10 working compile-time metafunctions I implemented in cppfront, from the set of metafunctions I described in my ISO C++ paper P0707. Since then, I’ve also implemented enum and union.
The most important thing about metafunctions is that they are compile-time library code that uses the reflection and code generation API, that lets the author of an ordinary C++ class type easily opt into a named set of defaults, requirements, and generated contents. This approach is essential to making the language simpler, because it lets us avoid hardwiring special “extra” types into the language and compiler.
In Cpp2, there’s no enum feature hardwired into the language. Instead you write an ordinary class type and just apply the enum metafunction:
// skat_game is declaratively a safe enumeration type: it has
// default/copy/move construction/assignment and <=> with
// std::strong_ordering, a minimal-size signed underlying type
// by default if the user didn't specify a type, no implicit
// conversion to/from the underlying type, in fact no public
// construction except copy construction so that it can never
// have a value different from its listed enumerators, inline
// constexpr enumerators with values that automatically start
// at 1 and increment by 1 if the user didn't write their own
// value, and conveniences like to_string()... the word "enum"
// carries all that meaning as a convenient and readable
// opt-in, without hardwiring "enum" specially into the language
//
skat_game: @enum<i16> type = {
diamonds := 9;
hearts; // 10
spades; // 11
clubs; // 12
grand := 20;
null := 23;
}
Consider hearts: It’s a member object declaration, but it doesn’t have a type (or a default value) which is normally illegal, but it’s okay because the @enum<i16> metafunction fills them in: It iterates over all the data members and gives each one the underlying type (here explicitly specified as i16, otherwise it would be computed as the smallest signed type that’s big enough), and an initializer (by default one higher than the previous enumerator).
Why have this metafunction on an ordinary C++ class, when C++ already has both C’s enum and C++11’s enum class? Because:
it keeps the language smaller and simpler, because it doesn’t hardwire special-purpose divergent splinter types into the language and compiler
(cue Beatles, and: “all you need is class (wa-wa, wa-wa-wa), all you need is class (wa-wa, wa-wa-wa)”);
it’s a better enum than C enum, because C enum is unscoped and not as strongly typed (it implicitly converts to the underlying type); and
it’s a better enum class than C++11 enum class, because it’s more flexible…
… consider: Because an enumeration type is now “just a type,” it just naturally can also have member functions and other things that are not possible for Cpp1 enums and enum classes (see this StackOverflow question):
janus: @enum type = {
past;
future;
flip: (inout this) == {
if this == past { this = future; }
else { this = past; }
}
}
There’s also a flag_enum variation with power-of-two semantics and an unsigned underlying type:
// file_attributes is declaratively a safe flag enum type:
// same as enum, but with a minimal-size unsigned underlying
// type by default, and values that automatically start at 1
// and rise by powers of two if the user didn't write their
// own value, and bitwise operations plus .has(flags),
// .set(flags), and .clear(flags)... the word "flag_enum"
// carries all that meaning as a convenient and readable
// opt-in without hardwiring "[Flags]" specially into the
// language
//
file_attributes: @flag_enum<u8> type = {
cached; // 1
current; // 2
obsolete; // 4
cached_and_current := cached | current;
}
Safe union metafunction
And you can declaratively opt into writing a safe discriminated union/variant type:
// name_or_number is declaratively a safe union/variant type:
// it has a discriminant that enforces only one alternative
// can be active at a time, members always have a name, and
// each member has .is_member() and .member() accessors...
// the word "union" carries all that meaning as a convenient
// and readable opt-in without hardwiring "union" specially
// into the language
//
name_or_number: @union type = {
name: std::string;
num : i32;
}
Why have this metafunction on an ordinary C++ class, when C++ already has both C’s union and C++11’s std::variant? Because:
it keeps the language smaller and simpler, because it doesn’t hardwire special-purpose divergent splinter types into the language and compiler
(cue the Beatles earworm again: “class is all you need, class is all you need…”);
it’s a better union than C union, because C union is unsafe; and
it’s a better variant than C++11 std::variant, because std::variant is hard to use because its alternatives are anonymous (as is the type itself; there’s no way to distinguish in the type system between a variant<int,string> that stores either an employee id or employee name, and a variant<int,string> that stores either a lucky number or a pet unicorn’s dominant color).
Each @union type has its own type-safe name, has clear and unambiguous named members, and safely encapsulates a discriminator to rule them all. Sure, it uses unsafe casts in the implementation, but they are fully encapsulated, where they can be tested once and be safe in all uses. That makes @union:
as easy to use as a C union,
as safe to use as a std::variant… and
as a bonus, because it’s an ordinary type, it can naturally have other things normal types can have, such as template parameter lists and member functions:
// a templated custom safe union
name_or_other: @union <T:type> type
= {
name : std::string;
other : T;
// a custom member function
to_string: (this) -> std::string = {
if is_name() { return name(); }
else if is_other() { return other() as std::string; }
else { return "invalid value"; }
}
}
main: () = {
x: name_or_other<int> = ();
x.set_other(42);
std::cout << x.other() * 3.14 << "\n";
std::cout << x.to_string(); // prints "42", but is legal whichever alternative is active
}
What’s next
For the rest of the year, I plan to:
continue self-hosting cppfront, i.e., migrate more of cppfront’s own code to be written in Cpp2 syntax, particularly now that I have enum and union (cppfront uses enum class and std::variant pervasively);
continue working my list of pending Cpp2 features and implementing them in cppfront; and
work with a few private alpha testers to start writing a bit of code in Cpp2, to alpha-test cppfront and also to alpha-test my (so far unpublished) draft documentation.
But first, one week from today, I’ll be at CppCon to give a talk about this progress and why full-fidelity compatibility with ISO C++ is essential (and what that means): “Cooperative C++ Evolution: Toward a TypeScript for C++.” I look forward to seeing many of you there!
Thanks again to C++ Now for inviting me to speak this year in glorious Aspen, Colorado, USA! It was nice to see many old friends again there and make a few new ones too.
The talk I gave there was just posted on YouTube, you can find it here:
At CppCon 2022, I argued for why we should try to make C++ 10x simpler and safer, and I presented my own incomplete experimental compiler, cppfront. Since then, cppfront has continued progressing: My spring update post covered the addition of types, a reflection API, and metafunctions, and this talk was given a week after that post and shows off those features with discussion and live demos.
This talk also clearly distinguishes between what I call the “Dart plan” and the “TypeScript plan” for aiming at a 10x improvement for an incumbent popular language. Both plans have value, but they have different priorities and therefore choose different constraints… most of all, they either embrace up-front the design constraint of perfect C++ interop compatibility, or they forgo it (forever; as I argue in the talk, it can never be achieved retroactively, except by starting over, because it’s a fundamental up-front constraint). No one else has tried the TypeScript plan for C++ yet, and I see value in trying it, and so that’s the plan I’m following for cppfront.
When people ask me “how is cppfront different from all the other projects trying to improve/replace C++?” my answer is “cppfront is on the TypeScript plan.” All the other past and present projects have been on the Dart plan, which again is a fine plan too, it just has different priorities and tradeoffs particularly around compatibility.
The video description has a topical guide linking to major points in the talk. Here below is a more detailed version of that topical guide… I hope you enjoy the talk!
2:35 – green-field experiments are great; but cppfront is about refreshing C++ itself
3:28 – “when I say compatibility .. I mean I can call any C++ code that exists today … with no shims, no thunks, no overheads, no indirections, no wrapping”
4:05 – can’t take a breaking change to existing code without breaking the world
5:22 – to me, the most impactful release of C++ was C++11, it most changed the way we wrote our code
6:20 – what if we could do C++11 again, but a coordinated set of features to internally evolve C++
6:52 – cppfront is an experiment in progress, still incomplete
Minutes ago, the ISO C++ committee finished its meeting in-person in Varna, Bulgaria and online via Zoom, where we formally began adopting features into C++26.
Our hosts, VMware and Chaos, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had nearly 180 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 20 nations. Also, at each meeting we regularly have new attendees who have never attended before, and this time there were 17 new first-time attendees, mostly in-person; to all of them, once again welcome!
The committee currently has 23 active subgroups, most of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their wortpkloads. You can find a brief summary of ISO procedures here.
ISO C++ is on a three-year development cycle, which includes a “feature freeze” about one year before we ship and publish that edition of the standard. For example, the feature freeze for C++23 was in early 2022.
But this doesn’t mean we only have two years’ worth of development time in the cycle and the third year is bug fixes and red tape. Instead, the subgroups are a three-stage pipeline and continue concurrently working on new feature development all the time, and the feature freezes are just the checkpoints where we pause loading new features into this particular train. So for the past year, as the subgroups finished work on fit-and-finish for the C++23 features, they also increasingly worked on C++26 features.
That showed this week, as we adopted the first 40 proposed change papers for C++26, many of which had been ready for a couple of meetings and were just waiting for the C++26 train to open for loading to be adopted. Of those 40 change papers, two were “apply the resolutions for all Ready issues” papers that applied a bunch of generally-minor changes. The other 38 were individual changes, everything from bug fixes to new features like hazard pointers and RCU.
Here are some of the highlights…
Adopted for C++26: Core language changes/features
The core language adopted 11 papers, including the following. Taking them in paper number order, which is roughly the order in which work started on the paper…
P2169 “A nice placeholder with no name” by Corentin Jabot and Michael Park officially adds support for the _ wildcard in C++26. Thanks to the authors for all their research and evidence for how it could be done in a backward-compatible way! Here are some examples that will now be legal as compilers start to support draft-C++26 syntax:
std::lock_guard _(mutex);
auto [x, y, _] = f();
inspect(foo) { _ => bar; };
Some compiler needs to implement -Wunderbar.
The palindromic P2552 “On the ignorability of standard attributes” by Timur Doumler sets forth the Three Laws of Robotics… er, I mean, the Three Rules of Ignorability for standard attributes. The Three Rules are a language design guideline for all current and future standard attributes going forward… see the paper for the full rules, but my informal summary is:
[Already in C++23] Rule 1. Standard attributes must be parseable (i.e., can’t just contain random nonsense).
[Already in C++23] Rule 2. Removing a standard attribute can’t change the program’s meaning: It can reduce the program’s possible legal behaviors, but it can’t invent new behaviors.
[New] Rule 3. Feature test macros shouldn’t pretend to support an attribute unless the implementation actually implements the attribute’s optional semantics (i.e., doesn’t just parse it but then ignore it).
P2558 “Add @, $, and ` to the basic character set” by Steve Downey is not a paper whose name was redacted for cussing; it’s a language extension paper that follows in C’s footsteps, and allows these characters to be used in valid C++ programs, and possibly in future C++ language evolution.
P2621 “UB? In my lexer?” by Corentin Jabot removes the possibility that just tokenizing C++ code can be a source of undefined behavior in a C++ compiler itself. (Did you know it could be UB? Now it can’t.) Note however that this does not remove all possible UB during compilation; future papers may address more of those compile-time UB sources.
P2738 “constexpr cast from void*: towards constexpr type-erasure” by Corentin Jabot and David Ledger takes another step toward powerful compile-time libraries, including enabling std::format to potentially support constexpr compile-time string formatting. Speaking of which…
P2741 “User-generated static_assert messages” by Corentin Jabot lets compile-time static_assert accept stringlike messages that are not string literals. For example, the popular {fmt} library (but not yet std::format, but see above!) supports constexpr string formatting, and so this code would work in C++26:
Together with P2738, an implementation of std::format that uses both of the above features would now be able to used in a static_assert.
Adopted for C++26: Standard library changes/features
The standard library adopted 28 papers, including the following. Starting again with the lowest paper number…
This first one gets the award for “being worked on the longest” (just look at the paper number, and the R revision number): P0792R14, “function_ref: A type-erased callable reference” by Vittorio Romeo, Zhihao Yuan, and Jarrad Waterloo adds function_ref<R(Args...)> as a vocabulary type with reference semantics for passing callable entities to the standard library.
P1383 “More constexpr for <cmath> and <complex>” by Oliver J. Rosten adds constexpr to over 100 more standard library functions. The march toward making increasing swathes of the standard library usable at compile time continues… Jason Turner is out there somewhere saying “Moar Constexpr!” and “constexpr all the things!”
Then, still in paper number order, we get to the “Freestanding group”:
P2510 “Formatting pointers” by Mark de Wever allows nice formatting of pointer values without incanting reinterpret_cast to an integer type first. For example, this will now work: format("{:P}", ptr);
P2530 “Hazard pointers for C++26” by Maged M. Michael, Michael Wong, Paul McKenney, Andrew Hunter, Daisy S. Hollman, JF Bastien, Hans Boehm, David Goldblatt, Frank Birbacher, and Mathias Stearn adds a subset of the Concurrency TS2 hazard pointer feature to add hazard pointer-based deferred cleanup to C++26.
P2545 “Read-Copy-Update (RCU)” by Paul McKenney, Michael Wong, Maged M. Michael, Andrew Hunter, Daisy Hollman, JF Bastien, Hans Boehm, David Goldblatt, Frank Birbacher, Erik Rigtorp, Tomasz Kamiński, Olivier Giroux, David Vernet, and Timur Doumler as another complementary way to do deferred cleanup in C++26.
P2548 “copyable_function” by Michael Hava adds a copyable replacement for std::function, modeled on move_only_function.
P2562 “constexpr stable sorting” by Oliver J. Rosten enables compile-time use of the standard library’s stable sorts (stable_sort, stable_partition, inplace_merge, and the ranges:: versions). Jason Turner is probably saying “Moar!”…
P2641 “Checking if a union alternative is active” by Barry Revzin and Daveed Vandevoorde introduces the consteval bool is_within_lifetime(const T* p) noexcept function, which works in certain compile-time contexts to find out whether p is a pointer to an object that is within its lifetime — such as checking the active member of a union, but during development the feature was made even more generally useful than just that one use case. (This is technically a core language feature, but it’s in one of the “magic std:: features that look like library functions but are actually implemented by the compiler” section of the standard, in this case the metaprogramming clause.)
Those are just 12 of the adopted papers as highlights… there were 16 more papers adopted that also apply more extensions and fixes for the C++26 standard library.
Other progress
We also adopted the C++26 schedule for our next three-year cycle. It’s the same as the schedule for C++23 but just with three years added everywhere, just as the C++23 schedule was in turn the same as the schedule for C++20 plus three years.
The language evolution subgroup (EWG) saw 30 presentations for papers during the week, mostly proposals targeting C++26, including fine-tuning for some of the above that made it into C++26 at this meeting.
The standard library evolution subgroup (LEWG) focused on advancing “big” papers in the queue that really benefit from face-to-face meetings. Notably, there is now design consensus on P1928 SIMD, P0876 Fibers, and P0843 inplace_vector, and those papers have been forwarded to the library wording specification subgroup (LWG) and may come up for adoption into C++26 at our next meeting in November. Additional progress was made on P0447 hive, P0260 Concurrent Queues, P1030 path_view, and P2781 constexpr_v.
The library wording specification subgroup (LWG) is now caught up with their backlog, and spent a lot of time iterating on the std::execution and sub_mdspan proposals (the latter was adopted this week).
The contracts subgroup made further progress on refining contract semantics targeting C++26, including to get consensus on removing build modes and having a contract violation handling API.
The concurrency and parallelism subgroup are still on track to move forward with std::execution and SIMD parallelism for C++26, which in the words of the subgroup chair will make C++26 a huge release for the concurrency and parallelism group.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the nearly 180 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in less than five months from now we’ll be meeting again in person + Zoom to continue adding features to C++26. Thank you again to everyone reading this for your interest and support for C++ and its standardization.












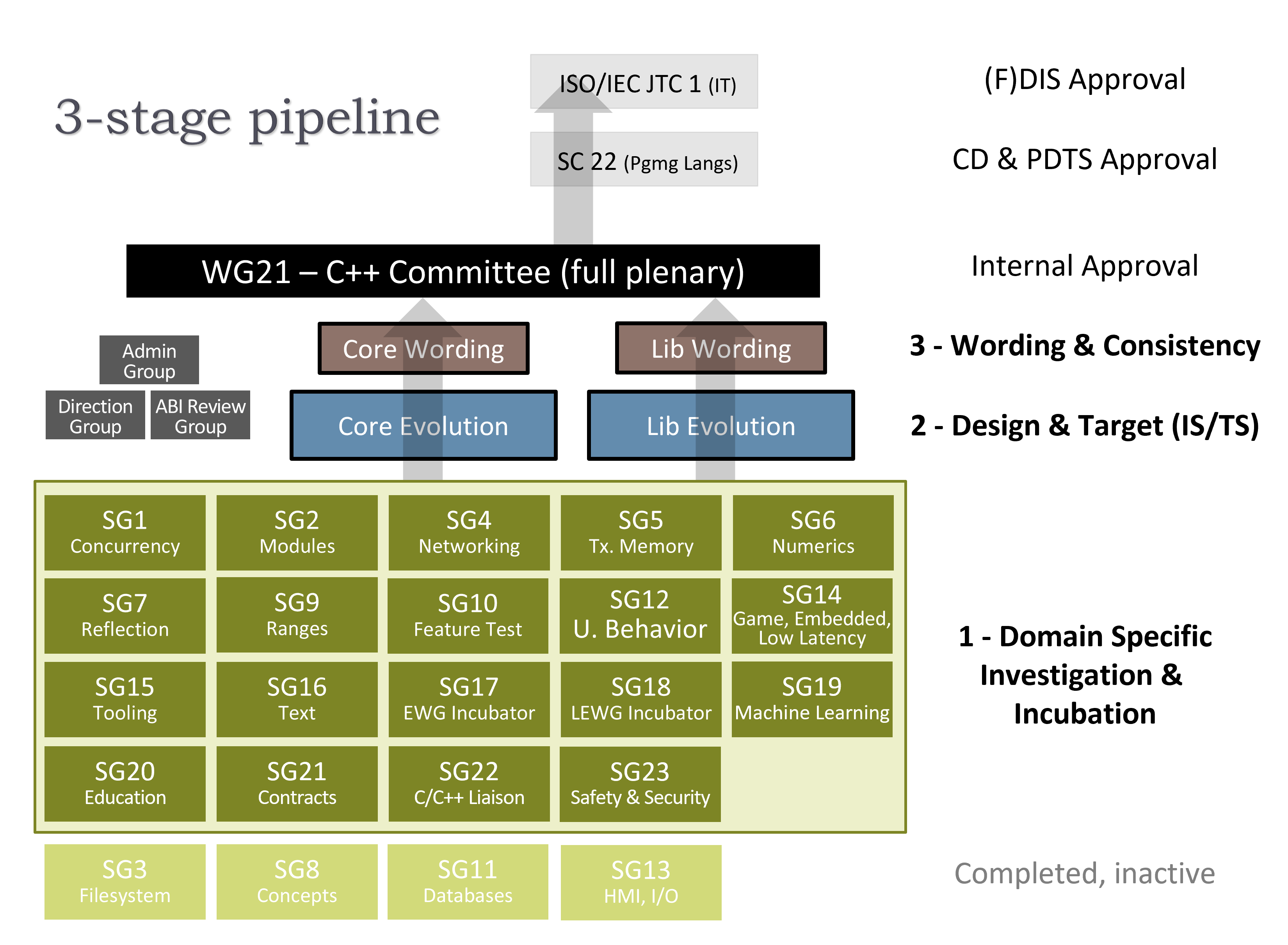{kind=link}