Since the 2022-12-31 year-end mini-update and the 2023-04-30 spring update, progress has continued on cppfront. (If you don’t know what this personal project is, please see the CppCon 2022 talk on YouTube for an overview, and the CppNow 2023 talk on YouTube for an interim update.)
I’ll be giving a major update next week at CppCon. I hope to see many of you there! In the meantime, here are some notes about what’s been happening since the spring update post, including:
- Acknowledgments and thanks
- Started self-hosting
- No data left behind: Mandatory explicit discard
requiresclauses- Generalized aliases+constexpr with
== - Safe
enumandflag_enummetafunctions - Safe
unionmetafunction - What’s next
Acknowledgments: Thank you!
Thank you to all these folks who have participated in the cppfront repo by opening issues and PRs, and to many more who participated on PR reviews and comment threads! These contributors represent people from high school and undergrad students to full professors, from commercial developers to conference speakers, and from every continent except Antarctica.
Started self-hosting
I haven’t spent a lot of time yet converting cppfront’s own code from today’s syntax 1 to my alternate syntax 2 (which I’m calling “Cpp1” and “Cpp2” for short), but I started with all of cppfront’s reflection API and metafunctions which are now mostly written in Cpp2. Here’s what that reflect.h2 file compilation looks like when compiled on the command line on my laptop:
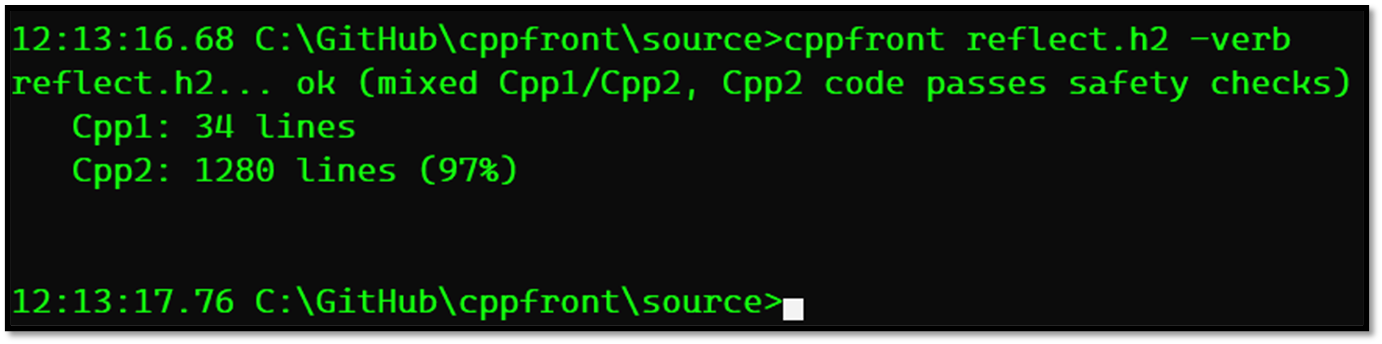
But note you can still build cppfront as all-today’s-C++ using any fairly recent C++20 compiler because I distribute the sources also as C++ (just as Bjarne distributed the cfront sources also as C).

No data left behind: Mandatory explicit discard
Initialization and data flow are fundamental to safe code, so from the outset I ensured that syntax 2 guaranteed initialization-before use, I made all converting constructors explicit by default… and I made [[nodiscard]] the default for return values (1-min talk clip).
The more I thought about [[nodiscard]], the more determined I was that data must never be silently lost, and data-lossy operations should be explicit. So I’ve decided to try an aggressive experiment:
- make “nodiscard” the law of the land, implicitly required all the time, with no opt-out…
- including when calling existing C++ libraries (including
std::) that were never designed for their return values to be treated as [[nodiscard]]!
Now, I wasn’t totally crazy: See the Design note: Explicit discard for details on how I first surveyed other languages’ designers about experience in their languages — notably C#, F#, and Python. In particular, F# does the same thing with .NET APIs — F# requires explicit |> ignore to discard unused return values, including for .NET APIs that were never designed for that and were largely written in other languages. Don Syme told me it has not been a significant pain point, and that was encouraging, so I’m following suit.
My experience so far is that it’s pretty painless, and I write about one explicit discard for every 200 lines of code, even when using the C++ standard library (which cppfront does pervasively, because the C++ standard library is the only library cppfront uses). And, so far, every time cppfront told me I had to write an explicit discard, I learned something useful (e.g., before this I never realized that emplace_back started to return something since C++17! push_back still doesn’t) and I found I liked that my code explicitly self-documented it was not looking at output values… my code looked better.
The way to do an explicit discard is to assign the result to the “don’t care” wildcard. It’s unobtrusive, but explicit and clear:
_ = vec.emplace_back(1,2,3);
Now all Cpp2-authored C++ functions are emitted as [[nodiscard]], except only for assignment and streaming operators because those are designed for chaining and every chain always ends with a discarded return.
And the whole language hangs together well: Explicit discard works very naturally with inout and out parameters too, not just return values. If you have a local variable x and pass it to an inout parameter, what if that’s the last use of the variable?
{
x := my_vector.begin();
std::advance(x, 2);
// ERROR, if param is Cpp2 'inout' or Cpp1 non-const '&'
}
In this example, that call to std::advance(x, 2); is a definite last use of x, and so Cpp2 will automatically pass x as an rvalue and make it a move candidate… and presto! the call won’t compile because you can’t pass an rvalue to a Cpp2 inout parameter (the same as a Cpp1 non-const-& parameter, so this correctly detects the output side effects also when calling existing C++ functions that take references to non-const). That’s a feature, not a bug, because if that’s the last use of x that means the function is not looking at x again, so it’s ignoring the “out” value of the std::advance(x, 2) function call, which is exactly like ignoring a return value. And the guidance is the same: If you really meant to do that, just explicitly discard x‘s final value:
{
x := my_vector.begin();
std::advance(x, 2);
_ = x; // all right, you said you meant it, carry on then...
}
Adding _ = x; afterward naturally makes that the last use of x instead. Problem solved, and it self-documents that the code really meant to ignore a function’s output value.
I really, really like how my C++ code’s data flow is explicit, and fully protected and safe, in syntax 2. And I’m very pleased to see how it just works naturally throughout the language — from universal guaranteed initialization, to explicit constructors by default, to banning implicitly discarding any values, to uniform treatment of returned values whether returned by return value or the “out” part of inout and out parameters, and all of it working also with existing C++ libraries so they’re safer and nicer to use from syntax 2. Data is always initialized, data is never silently lost, data flow is always visible. Data is precious, and it’s always safe. This feels right and proper to me.
requires clauses
I also added support for requires clauses, so now you can write those on all templates. The cppfront implementation was already generating some requires clauses already (see this 1-min video clip). Now programmers can write their own too.
This required a bit of fighting with a GCC 10 bug about requires-clauses on declarations, that was fixed in GCC 11+ but was never backported. But because this was the only problem I’ve encountered with GCC 10 that I couldn’t paper over, and because I could give a clear diagnostic that a few features in Cpp2 that rely on requires clauses aren’t supported on GCC 10, so far I’ve been able to retain GCC 10 as a supported compiler and emit diagnostics if you try to use those few features it doesn’t support. GCC 11 and higher are all fine and support all Cpp2 semantics.
Generalized aliases+constexpr with ==
In the April blog post, I mentioned I needed a way to write type and namespace aliases, and that because all Cpp2 declarations are of the form thing : type = value, I decided to try using the same syntax but with == to denote “always equal to.”
// namespace alias
lit: namespace == ::std::literals;
// type alias
pmr_vec: <T> type
== std::vector<T, std::pmr::polymorphic_allocator<T>>;
I think this clearly denotes that lit is always the same as ::std::literals, and pmr_vec<int> is always the same as std::vector<int, std::pmr::polymorphic_allocator<int>>.
Since then, I’ve thought about how this should be best extended to functions and objects, and I realized the requirements seem to overlap with something else I needed to support: constexpr functions and objects. Which, after all, are functions/objects that return/have “always the same values” known at compile time…
// function with "always the same value" (constexpr function)
increment: (value: int) -> int == value+1;
// Cpp2 lets you omit { return } around 1-line bodies
// object with "always the same value" (constexpr object)
forty_two: i64 == 42;
I particularly needed these in order to write the enum metafunctions…
Safe enum and flag_enum metafunctions
In the spring update blog post, I described the first 10 working compile-time metafunctions I implemented in cppfront, from the set of metafunctions I described in my ISO C++ paper P0707. Since then, I’ve also implemented enum and union.
The most important thing about metafunctions is that they are compile-time library code that uses the reflection and code generation API, that lets the author of an ordinary C++ class type easily opt into a named set of defaults, requirements, and generated contents. This approach is essential to making the language simpler, because it lets us avoid hardwiring special “extra” types into the language and compiler.
In Cpp2, there’s no enum feature hardwired into the language. Instead you write an ordinary class type and just apply the enum metafunction:
// skat_game is declaratively a safe enumeration type: it has
// default/copy/move construction/assignment and <=> with
// std::strong_ordering, a minimal-size signed underlying type
// by default if the user didn't specify a type, no implicit
// conversion to/from the underlying type, in fact no public
// construction except copy construction so that it can never
// have a value different from its listed enumerators, inline
// constexpr enumerators with values that automatically start
// at 1 and increment by 1 if the user didn't write their own
// value, and conveniences like to_string()... the word "enum"
// carries all that meaning as a convenient and readable
// opt-in, without hardwiring "enum" specially into the language
//
skat_game: @enum<i16> type = {
diamonds := 9;
hearts; // 10
spades; // 11
clubs; // 12
grand := 20;
null := 23;
}
Consider hearts: It’s a member object declaration, but it doesn’t have a type (or a default value) which is normally illegal, but it’s okay because the @enum<i16> metafunction fills them in: It iterates over all the data members and gives each one the underlying type (here explicitly specified as i16, otherwise it would be computed as the smallest signed type that’s big enough), and an initializer (by default one higher than the previous enumerator).
Why have this metafunction on an ordinary C++ class, when C++ already has both C’s enum and C++11’s enum class? Because:
- it keeps the language smaller and simpler, because it doesn’t hardwire special-purpose divergent splinter types into the language and compiler
- (cue Beatles, and: “all you need is class (wa-wa, wa-wa-wa), all you need is class (wa-wa, wa-wa-wa)”);
- it’s a better
enumthan Cenum, because Cenumis unscoped and not as strongly typed (it implicitly converts to the underlying type); and - it’s a better
enum classthan C++11enum class, because it’s more flexible…
… consider: Because an enumeration type is now “just a type,” it just naturally can also have member functions and other things that are not possible for Cpp1 enums and enum classes (see this StackOverflow question):
janus: @enum type = {
past;
future;
flip: (inout this) == {
if this == past { this = future; }
else { this = past; }
}
}
There’s also a flag_enum variation with power-of-two semantics and an unsigned underlying type:
// file_attributes is declaratively a safe flag enum type:
// same as enum, but with a minimal-size unsigned underlying
// type by default, and values that automatically start at 1
// and rise by powers of two if the user didn't write their
// own value, and bitwise operations plus .has(flags),
// .set(flags), and .clear(flags)... the word "flag_enum"
// carries all that meaning as a convenient and readable
// opt-in without hardwiring "[Flags]" specially into the
// language
//
file_attributes: @flag_enum<u8> type = {
cached; // 1
current; // 2
obsolete; // 4
cached_and_current := cached | current;
}
Safe union metafunction
And you can declaratively opt into writing a safe discriminated union/variant type:
// name_or_number is declaratively a safe union/variant type:
// it has a discriminant that enforces only one alternative
// can be active at a time, members always have a name, and
// each member has .is_member() and .member() accessors...
// the word "union" carries all that meaning as a convenient
// and readable opt-in without hardwiring "union" specially
// into the language
//
name_or_number: @union type = {
name: std::string;
num : i32;
}
Why have this metafunction on an ordinary C++ class, when C++ already has both C’s union and C++11’s std::variant? Because:
- it keeps the language smaller and simpler, because it doesn’t hardwire special-purpose divergent splinter types into the language and compiler
- (cue the Beatles earworm again: “class is all you need, class is all you need…”);
- it’s a better
unionthan Cunion, because Cunionis unsafe; and - it’s a better
variantthan C++11std::variant, becausestd::variantis hard to use because its alternatives are anonymous (as is the type itself; there’s no way to distinguish in the type system between avariant<int,string>that stores either an employee id or employee name, and avariant<int,string>that stores either a lucky number or a pet unicorn’s dominant color).
Each @union type has its own type-safe name, has clear and unambiguous named members, and safely encapsulates a discriminator to rule them all. Sure, it uses unsafe casts in the implementation, but they are fully encapsulated, where they can be tested once and be safe in all uses. That makes @union:
- as easy to use as a C
union, - as safe to use as a
std::variant… and - as a bonus, because it’s an ordinary type, it can naturally have other things normal types can have, such as template parameter lists and member functions:
// a templated custom safe union
name_or_other: @union <T:type> type
= {
name : std::string;
other : T;
// a custom member function
to_string: (this) -> std::string = {
if is_name() { return name(); }
else if is_other() { return other() as std::string; }
else { return "invalid value"; }
}
}
main: () = {
x: name_or_other<int> = ();
x.set_other(42);
std::cout << x.other() * 3.14 << "\n";
std::cout << x.to_string(); // prints "42", but is legal whichever alternative is active
}
What’s next
For the rest of the year, I plan to:
- continue self-hosting cppfront, i.e., migrate more of cppfront’s own code to be written in Cpp2 syntax, particularly now that I have
enumandunion(cppfront usesenum classandstd::variantpervasively); - continue working my list of pending Cpp2 features and implementing them in cppfront; and
- work with a few private alpha testers to start writing a bit of code in Cpp2, to alpha-test cppfront and also to alpha-test my (so far unpublished) draft documentation.
But first, one week from today, I’ll be at CppCon to give a talk about this progress and why full-fidelity compatibility with ISO C++ is essential (and what that means): “Cooperative C++ Evolution: Toward a TypeScript for C++.” I look forward to seeing many of you there!
