On Saturday, the ISO C++ committee completed technical work on C++26 in (partly) sunny London Croydon, UK. We resolved the remaining international comments on the C++26 draft, and are now producing the final document to be sent out for its international approval ballot (Draft International Standard, or DIS) and final editorial work, to be published in the near future by ISO.
This meeting was hosted by Phil Nash of Shaved Yaks, and the Standard C++ Foundation. Our hosts arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had about 210 attendees, about 130 in-person and 80 remote via Zoom, formally representing 24 nations. At each meeting we regularly have new guest attendees who have never attended before, and this time there were 24 new guest attendees, mostly in-person, in addition to new attendees who are official national body representatives. To all of them, once again welcome!
The committee currently has 23 active subgroups, nine of which met in 6 parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads. We had three technical evening sessions on C++ compiler/library implementations, memory safety, and quantities/units. You can find a brief summary of ISO procedures here.
C++26 is complete: The most compelling release since C++11
Per our published C++26 schedule, this was our final meeting to finish technical work on C++26. No features were added or removed; we just handled fit-and-finish issues and primarily focused on finishing addressing the 411 national body comments we received in the summer’s international comment ballot (Committee Draft, or CD).
If you’re wondering “what are the Big Reasons why should I care about C++26?” then the best place to start is with the C++26 Fab Four Features…
“In June 2025, C++ crossed a Rubicon: it handed us the keys to its own machinery. For the first time, C++ can describe itself—and generate more. The first compile-time reflection features in draft C++26 mark the most transformative turning point in our language’s history by giving us the most powerful new engine for expressing efficient abstractions that C++ has ever had, and we’ll need the next decade to discover what this rocket can do.”
(2) Less UB for more memory safety: C++ code is more memory safe just by recompiling as C++26
C++26 has important memory safety improvements that you get just by recompiling your existing C++ code with no changes. The improvements come in two major ways.
No more undefined behavior (UB) for reading uninitialized local variables. This whole category of potential vulnerabilities disappears in C++26, just by recompiling your code as C++26. For more details, see my March 2025 trip report.
The hardened standard library provides initial cross-platform library security guarantees, including bounds safety for dozens of the most widely used bounded operations on common standard types, including vector, span, string, string_view, and more. For details, see my February 2025 trip report and run (don’t walk) to read the November 2025 ACM Queue article “Practical Security in Production: Hardening the C++ Standard Library at Massive Scale” to learn how this is already deployed across Apple platforms and Google services, hundreds of millions of lines of code, with on average 0.3% (a fraction of 1%) performance overhead. From the paper:
“The final tally after the rollout was remarkable. Across hundreds of millions of lines of C++ at Google, only five services opted out entirely because of reliability or performance concerns. Work is ongoing to eliminate the need for these few remaining exceptions, with the goal of reaching universal adoption.
Even more telling, the fine-grained API [to opt out] for unsafe access was used in just seven distinct places, all of which were surgical changes made by the security team to reclaim performance in code that was correct but difficult for the compiler to analyze. This widespread adoption stands as the strongest possible testament to the practicality of the hardening checks in real-world production environments.”
This is no just-on-paper design. At Google alone, it has already fixed over 1,000 bugs, is projected to prevent 1,000 to 2,000 bugs a year, and has reduced the segfault rate across the production fleet by 30%.
And, now, it is standardized for everyone in C++26. Thank you, Apple and Google and all the standard library implementers!
(3) Contracts for functional safety: pre, post, contract_assert
In C++26, we also have language contracts: preconditions and postconditions on function declarations and a language-supported assertion statement, all of which are infinitely better than C’s assert macro.
Note that some smart and respected ISO C++ committee experts have sustained technical concerns about contracts. For my summary of the contracts feature and all the major repeated concerns (with my opinions about them, which could be wrong!), see my CppCon 2025 contracts talk. In February 2025 when we took the plenary poll to adopt contracts in the C++26 working draft (“merge it to trunk”), the vote was:
100 in favor, 14 opposed, and 12 abstaining
Since then, the concerns have all been deeply rediscussed for the last three meetings thanks to thoughtful and high-quality technical papers; all of those papers have continued to be fully heard, often for multiple days and at many telecons between meetings. At our previous meeting in November 2025, we did fix a couple of contracts specification bugs thanks to this feedback! Yesterday, when we took the plenary poll to finalize and ship the C++26 standard, the vote was non-unanimous primarily because of the sustained concerns about contracts:
114 in favor, 12 opposed, and 3 abstaining
The unusually low number of abstentions shows that virtually all our experts now feel sure about their technical opinions, either for or against contracts. After extensive scrutiny, the committee’s opinion is clear: The ISO C++ committee still wants contracts, and so contracts have stayed in C++26.
(4) std::execution (aka “Sender/Receiver”)
std::execution is what I call “C++’s async model”: It provides a unified framework to express and control concurrency and parallelism. For details, see my July 2024 trip report. It also happens to have some important safety properties because it makes it easier to write programs that use structured (rigorously lifetime-nested) concurrency and parallelism to be data-race-free by construction. That’s a big deal.
I do want to write a warning though: This feature is great (my company has already been using it in production) but it’s currently harder to adopt than most C++ features because it lacks great documentation and is missing some “fingers-and-toes” libraries. For now, do expect great results from std::execution, but also expect to spend some initial time on learning with the help of a friend who already knows it well, and to write a few helper adapter libraries to integrate std::execution with your existing async code.
C++26 adoption will be fast
There are two reasons I expect C++26 to be adopted in industry very quickly compared with C++17, C++20, and C++23.
First, user demand for this feature set is extraordinarily high. C++11 was our last “big and impactful” release that was chock full of features that the vast majority of C++ developers would use daily (auto, range-for, lambdas, smart pointers, move semantics, threads, mutexes, …). Since then, our followup triennial standards have also had some ‘big’ features like parallel STL, concepts, coroutines, and modules, but the reality is that those weren’t as massively impactful for all C++ developers as C++11’s features were, or as C++26’s marquee features of reflection and safety hardening will be now. So even if your company has been slow to enable the C++20 switch, I think you’ll find they’ll be much faster to enable C++26. There’s just so much more high-demand value that makes it an exciting and exceptionally useful release for everyone who uses C++.
Second, conforming compiler and standard library implementations are coming quickly. Throughout the development of C++26, at any given point both GCC and Clang had already implemented two-thirds of C++26 features. Today, GCC already has reflection and contracts merged in trunk, awaiting release.
Work on C++29, especially on more memory safety and profiles
At this meeting we also adopted the schedule for C++29, which will be another three-year release cycle. To no one’s surprise, a major focus of the discussion about C++29-timeframe material was about further increasing memory safety.
This week, the main language evolution subgroup (EWG) reviewed updates on several ongoing proposals in the area of further type/memory-safety improvements for C++29, including: to pursue proposals to further reduce undefined behavior to be seen again in EWG for possible inclusion in C++29; and to pursue further development of safety profile papers in the safety and security subgroup (SG23) to then be brought to EWG targeting C++29. SG23 specifically worked on Bjarne Stroustrup’s P3984 type safety profile using the proposed general profiles framework by Gabriel Dos Reis.
Besides those sessions, type and memory safety was extensively discussed in two additional large-attendance sessions: an evening session on Wednesday night attended by the majority of the committee, and in an EWG memory safety dedicated session all Friday afternoon attended by about 90 experts. In particular, I want to thank Oliver Hunt of Apple for presenting the practical experience report P4158R0, “Subsetting and restricting C++ for memory safety,” reporting how WebKit hardened over 4 million lines of code using a subset-of-superset approach (like Stroustrup’s Profiles) and showing how that has already made a profound difference in the security of C++ code in WebKit at scale. Here are a few highlights from the introduction slide (emphasis added):
Closes multiple classes of vulnerabilities,current policies would have prevented majority of historical exploits
Found (and prevented exploitability) of new and existing bugs”
C++29 is already set to build even more on the safety improvements already in C++26, and I for one welcome our new era of safer-by-default-and-still-zero-overhead-efficient-C++ overlords. C++26 is the first step into a fundamentally new era: This isn’t our grandparents’ wild-west UB-filled anything-goes C++ anymore. But even as C++ moves to being more memory-safe by default, it’s staying true to C++’s enduring core of the zero-overhead principle… you don’t pay for what you don’t use, and even when some safety is so cheap that we can turn it on by default in the language you will always have a way to opt out when you need to get the last ounce of performance in that hot path or inner loop.
We did other work, including other things related to functional safety: EWG reviewed additional plans for applying contract checks in the language and standard library. The numerics subgroup (SG6) and library incubation subgroup (SG18) progressed P3045R7, “Quantities and units library” by Mateusz Pusz, Dominik Berner, Johel Ernesto Guerrero Peña, Chip Hogg, Nicolas Holthaus, Roth Michaels and Vincent Reverdy to the main library evolution subgroup (LEWG), and we had an evening session on the topic for the whole committee on Thursday evening. I encourage reading section 7.1 “Safety concerns” in the paper, including how technology like that in this paper could have improved Black Sabbath’s 1983 tour (which was hilariously lampooned in, of course, This Is Spinal Tap).
Thank you again to the about 210 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in less than three months from now we’ll be meeting again in Czechia and online to start adding features to C++29, with many subgroup telecons already scheduled between now and then. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
2025 was another great year for C++. It shows in the numbers
Before we dive into the data below, let’s put the most important question up front: Why have C++ and Rust been the fastest-growing major programming languages from 2022 to 2025?
Primarily, it’s because throughout the history of computing “software taketh away faster than hardware giveth.” There is enduring demand for efficient languages because our demand for solving ever-larger computing problems consistently outstrips our ability to build greater computing capacity, with no end in sight. [6] Every few years, people wonder whether our hardware is just too fast to be useful, until the future’s next big software demand breaks across the industry in a huge wake-up moment of the kind that iOS delivered in 2007 and ChatGPT delivered in November 2022. AI is only the latest source of demand to squeeze the most performance out of available hardware.
The world’s two biggest computing constraints in 2025
Quick quiz: What are the two biggest constraints on computing growth in 2025? What’s in shortest supply?
Take a moment to answer that yourself before reading on…
— — —
If you answered exactly “power and chips,” you’re right — and in the right order.
Chips are only our #2 bottleneck. It’s well known that the hyperscalars are competing hard to get access to chips. That’s why NVIDIA is now the world’s most valuable company, and TSMC is such a behemoth that it’s our entire world’s greatest single point of failure.
But many people don’t realize: Power is the #1 constraint in 2025. Did you notice that all the recent OpenAI deals were expressed in terms of gigawatts? Let’s consider what three C-level executives said on their most recent earnings calls. [1]
[Microsoft Azure’s constraint is] not actually being short GPUs and CPUs per se, we were short the space or the power, is the language we use, to put them in.
[AWS added] more than 3.8 gigawatts of power in the past 12 months, more than any other cloud provider. To put that into perspective, we’re now double the power capacity that AWS was in 2022, and we’re on track to double again by 2027.
The most important thing is, in the end, you still only have 1 gigawatt of power. One gigawatt data centers, 1 gigawatt power. … That 1 gigawatt translates directly. Your performance per watt translates directly, absolutely directly, to your revenues.
That’s why the future is enduringly bright for languages that are efficient in “performance per watt” and “performance per transistor.” The size of computing problems we want to solve has routinely outstripped our computing supply for the past 80 years; I know of no reason why that would change in the next 80 years. [2]
The list of major portable languages that target those key durable metrics is very short: C, C++, and Rust. [3] And so it’s no surprise to see that in 2025 all three continued experiencing healthy growth, but especially C++ and Rust.
Let’s take a look.
The data in 2025: Programming keeps growing by leaps and bounds, and C++ and Rust are growing fastest
Programming is a hot market, and programmers are in long-term high-growth demand. (AI is not changing this, and will not change it; see Appendix.)
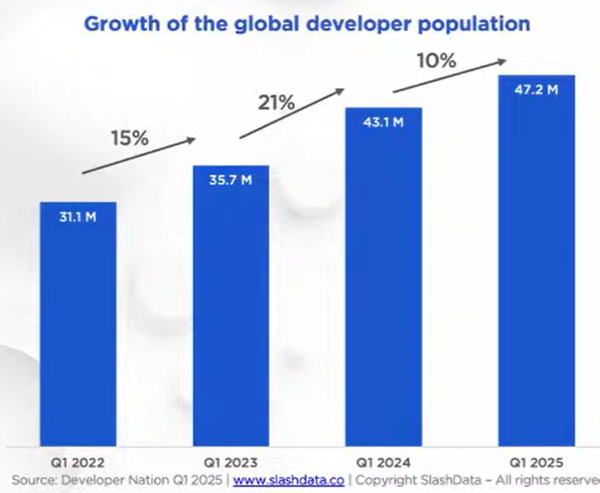
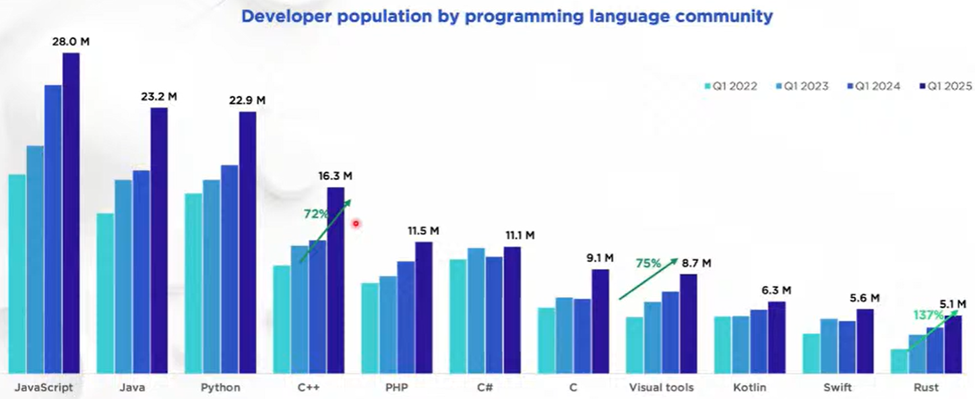
“Global developer population trends 2025” (SlashData, 2025) reports that in the past three years the global developer population grew about 50%, from just over 31 million to just over 47 million. (Other sources are consistent with that: IDC forecasts that this growth will continue, to over 57 million developers by 2028. JetBrains reports similar numbers of professional developers; their numbers are smaller because they exclude students and hobbyists.) And which two languages are growing the fastest (highest percentage growth from 2022 to 2025)? Rust, and C++.
To put C++’s growth in context:
Compared to all languages: There are now more C++ developers than the #1 language had just four years ago.
Compared to Rust: Each of C++, Python, and Java just added about as many developers in one year as there are Rust total developers in the world.
C++ is a living language whose core job to be done is to make the most of hardware, and it is continually evolving to stay relevant to the changing hardware landscape. The new C++26 standard contains additional support for hardware parallelism on the latest CPUs and GPUs, notably adding more support for SIMD types for intra-CPU vector parallelism, and the std::execution Sender/Receiver model for general multi-CPU and GPU concurrency and parallelism.
But wait — how could this growth be happening? Isn’t C++ “too unsafe to use,” according to a spate of popular press releases and tweets by a small number of loud voices over the past few years?
Let’s tackle that next…
Safety (type/memory safety, functional safety) and security
C++’s rate of security vulnerabilities has been far overblown in the press primarily because some reports are counting only programming language vulnerabilities when those are a smaller minority every year, and because statistics conflate C and C++. Let’s consider those two things separately.
First, the industry’s security problem is mostly not about programming language insecurity.
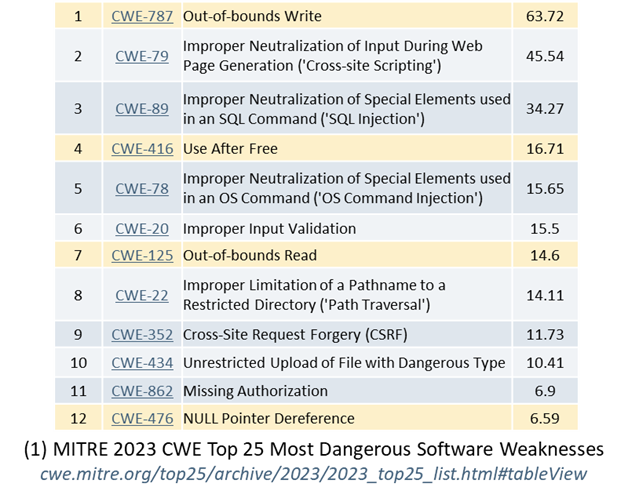
Year after year, and again in 2025, in the MITRE “CWE Top 25 Most Dangerous Software Weaknesses” (mitre.org, 2025) only three of the top 10 “most dangerous software weaknesses” are related to language safety properties. Of those three, two (out-of-bounds write and out-of-bounds read) are directly and dramatically improved in C++26’s hardened C++ standard library which does bounds-checking for the most widely used bounded operations (see below). And that list is only about software weaknesses, when more and more exploits bypass software entirely.
Why are vulnerabilities increasingly not about language issues, or even about software at all? Because we have been hardening our software; this is why the cost of zero-day exploits has kept rising, from thousands to millions of dollars. So attackers stop pursuing that as much, and switch to target the next slowest animal in the herd. For example, “CrowdStrike 2025 Global Threat Report” (CrowdStrike, 2025) reports that “79% of [cybersecurity intrusion] detections were malware-free,” not involving programming language exploits. Instead, there was huge growth not only in non-language exploits, but even in non-software exploits, including a “442% growth in vishing [voice phishing via phone calls and voice messages] operations between the first and second half of 2024.”
Why go to the trouble of writing an exploit for a use-after-free bug to infect someone’s computer with malware which is getting more expensive every year, when it’s easier to do some cross-site scripting that doesn’t depend on a programming language insecurity, and it’s easier still to ignore the software entirely and just convince the user to tell you their password on the phone?
Second, for the subset that is about programming language insecurity, the problem child is C, not C++.
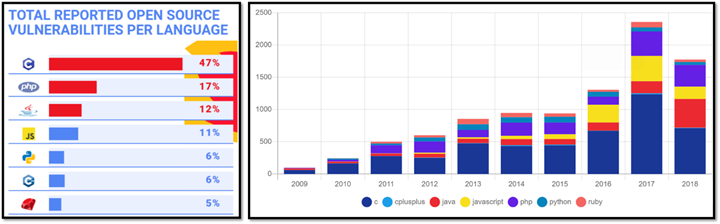
A serious problem is that vulnerability statistics almost always conflate C and C++; it’s very hard to find good public sources that distinguish them. The only reputable public study I know of that distinguished between C and C++ is Mend.io’s as reported in “What are the most secure programming languages?” (Mend.io, 2019). Although the data is from 2019, as you can see the results are consistent across years.
Can’t see the C++ bar? Pinch to zoom. 😉
Although C++’s memory safety has always been much closer to that of other modern popular languages than to that of C, we do have room for improvement and we’re doing even better in the newest C++ standard about to be released, C++26. It delivers two major security improvements, where you can just recompile your code as C++26 and it’s significantly more secure:
C++26 eliminates undefined behavior from uninitialized local variables. [4] How needed is this? Well, it directly addresses a Reddit r/cpp complaint posted just today while I was finishing this post: “The production bug that made me care about undefined behavior” (Reddit, December 30, 2025).
C++26 adds bounds safety to the C++ standard library in a “hardened” mode that bounds-checks the most widely used bounded operations. “Practical Security in Production” (ACM Queue, November 2025) reports that it has already been used at scale across Apple platforms (including WebKit) and nearly all Google services and Chrome (100s of millions of lines of code) with tiny space and time overhead (fraction of one percent each), and “is projected to prevent 1,000 to 2,000 new bugs annually” at Google alone.
Additionally, C++26 adds functional safety via contracts: preconditions, postconditions, and contract assertions in the language, that programmers can use to check that their programs behave as intended well beyond just memory safety.
Beyond C++26, in the next couple of years I expect to see proposals to:
harden more of the standard library
remove more undefined behavior by turning it into erroneous behavior, turning it into language-enforced contracts, or forbidding it via subsets that ban unsafe features by default unless we explicitly opt in (aka profiles)
I know of people who’ve been asking for C++ evolution to slow down a little to let compilers and users catch up, something like we did for C++03. But we like all this extra security, too. So, just spitballing here, but hypothetically:
What if we focused C++29, the next release cycle of C++, to only issue-list-level items (bug fixes and polish, not new features) and the above “hardening” list (add more library hardening, remove more language undefined behavior)?
I’m intrigued by this idea, not because security is C++’s #1 burning issue — it isn’t, C++ usage is continuing to grow by leaps and bounds — but because it could address both the “let’s pause to stabilize” and “let’s harden up even more” motivations. Focus is about saying no.
Conclusion
Programming is growing fast. C++ is growing very fast, with a healthy long-term future because it’s deeply aligned with the overarching 80-year trend that computing demand always outstrips supply. C++ is a living language that continually adapts to its environment to fulfill its core mission, tracking what developers need to make the most of hardware.
And it shows in the numbers.
Here’s to C++’s great 2025, and its rosy outlook in 2026! I hope you have an enjoyable rest of the holiday period, and see you again in 2026.
Acknowledgments
Thanks to Saeed Amrollahi Boyouki, Mark Hoemmen and Bjarne Stroustrup for motivating me to write this post and/or providing feedback.
Appendix: AI
Finally, let’s talk about the topic no article can avoid: AI.
C++ is foundational to current AI. If you’re running AI, you’re running CUDA (or TensorFlow or similar) — directly or indirectly — and if you’re running CUDA (or TensorFlow or similar), you’re probably running C++. CUDA is primarily available as a C++ extension. There’s always room for DSLs at the leading edge, but for general-purpose AI most high-performance deployment and inference is implemented in C++, even if people are writing higher-level code in other languages (e.g., Python).
But more broadly than just C++: What about AI generally? Will it take all our jobs? (Spoiler: No.)
AI is a wonderful and transformational tool that greatly reduces rote work, including problems that have already been solved, where the LLM is trained on the known solutions. ButAI cannot understand, and therefore can’t solve, new problems — which is most of the current and long-term growth in our industry.
What does that imply? Two main things, in my opinion…
First, I think that people who think AI isn’t a major game-changer are fooling themselves.
To me, AI is on par with the wheel (back in the mists of time), the calculator (back in the 1970s), and the Internet (back in the 1990s). [5] Each of those has been a game-changing tool to accelerate (not replace) human work, and each led to more (not less) human production and productivity.
I strongly recommend checking out Adam Unikowsky’s “Automating Oral Argument” (Substack, July 7, 2025). Unikowsky took his own actual oral arguments before the United States Supreme Court and showed how well 2025-era Claude can do as a Supreme Court-level lawyer, and with what strengths and weaknesses. Search for “Here is the AI oral argument” and click on the audio player, which is a recording of an actual Supreme Court session and replaces only Unikowsky’s responses with his AI-generated voice saying the AI-generated text argument directly responding to each of the justices’ actual questions; the other voices are the real Supreme Court justices. (Spoiler: “Objectively, this is an outstanding oral argument.”)
Second, I think that people who think AI is going to put a large fraction of programmers out of work are fooling themselves.
We’ve just seen that, today, three years after ChatGPT took the world by storm, the number of human programmers is growing as fast as ever. Even the companies that are the biggest boosters of the “AI will replace programmers” meme are actually aggressively growing, not reducing, their human programmer workforces.
Consider what three more C-level executives are saying.
Sam Schillace, Microsoft Deputy CTO (Substack, December 19, 2025) is pretty AI-ebullient, but I do agree with this part he says well, and which resonates directly with Unikowsky’s experience above:
If your job is fundamentally “follow complex instructions and push buttons,” AI will come for it eventually.
People were telling me [that] with AI we can replace all of our junior people in our company. I was like that’s … one of the dumbest things I’ve ever heard. … I think AI has the potential to transform every single industry, every single company, and every single job. But it doesn’t mean they go away. It has transformed them, not replaced them.
I think [AI]’s a huge force multiplier personally for human creativity, problem solving … If software costs half as much to write, I can either do it with half as many people, but [due to] core competitive forces … I will [actually] need the same number of people, I would just need to do a better job of making higher quality technology. … People shouldn’t be afraid of AI taking their job … they should be afraid of someone who’s really good at AI [and therefore more efficient] taking their job.
So if we extend the question of “what are our top constraints on software?” to include not only hardware and power, the #3 long-term constraint is clear: We are chronically short of skilled human programmers. Humans are not being replaced en masse, not most of us; we are being made more productive, and we’re needed more than ever. As I wrote above: “Programming is a hot market, and programmers are in long-term high-growth demand.”
Endnotes
[1] It’s actually great news that Big Tech is spending heavily on power, because the gigawatt capacity we build today is a long-term asset that will keep working for 15 to 20+ years, whether the companies that initially build that capacity survive or get absorbed. That’s important because it means all the power generation being built out today to satisfy demand in the current “AI bubble” will continue to be around when the next major demand for compute after AI comes along. See Ben Thompson’s great writing, such as “The Benefits of Bubbles” (Stratechery, November 2025).
[2] The Hitchhiker’s Guide to the Galaxy contains two opposite ideas, both fun but improbable: (1) The problem of being “too compute-constrained”: Deep Thought, the size of a city, wouldn’t really be allowed to run for 7.5 million years; you’d build a million cities. (2) The problem of having “too much excess compute capacity”: By the time a Marvin with a “brain the size of a planet” was built, he wouldn’t really be bored; we’d already be trying to solve problems the size of the solar system.
[3] This is about “general-purpose” coding. Code at the leading specialized edges will always include use of custom DSLs.
[4] This means that compiling plain C code (that is in the C/C++ intersection) as C++26 also automatically makes it more correct and more secure. This isn’t new; compiling C code as C++ and having the C code be more correct has been true since the 1980s.
[5] If you’re my age, you remember when your teacher fretted that letting you use a calculator would harm your education. More of you remember similar angsting about letting students google the internet. Now we see the same fears with AI — as if we could stop it or any of those others even if we should. And we shouldn’t; each time, we re-learn the lesson that teaching students to use such tools should be part of their education because using tools makes us more productive.
[6] This is not the same as Wirth’s Law, that “software is getting slower more rapidly than hardware is becoming faster.” Wirth’s observation was that the overheads of operating systems and higher-level runtimes and other costly abstractions were becoming ever heavier over time, so that a program to solve the same problem was getting more and more inefficient and soaking up more hardware capacity than it used to; for example, printing “Hello world” really does take far more power and hardware when written in modern Java than it did in Commodore 64 BASIC. That doesn’t apply to C++ which is not getting slower over time; C++ continues to be at least as efficient as low-level C for most uses. No, the key point I’m making here is very different: that the problems the software is tackling are growing faster than hardware is becoming faster.
Last month, I was having dinner with a group and someone at the table was excitedly sharing how they were using agentic AI to create and merge PRs for them, with some review but with a lot of trust and automation. I admitted that I could be comfortable with some limited uses for that, such as generating unit tests at scale, but not for bug fixes or other actual changes to production code; I’m a long way away from trusting an AI to act for me that freely. Call me a Luddite, or just a control freak, but I won’t commit non-test code unless I (or some expert I trust) have reviewed it in detail and fully understand it. (Even test code needs some review or safeguards, because it’s still code running in your development environment.)
My knee-jerk reaction against AI-generated PRs and merges puzzled the table, so I cited some of Bruce Schneier’s recent posts to explain why.
This week, after my Tuesday night PDXCPP user group talk, similar AI questions came up again in the Q&A.
Because I keep getting asked about this even though I’m not an AI or security expert, here are links to two of Schneier’s recent posts, because he is an expert and cites other experts… and then finally a link to Ken Thompson’s classic short “trusting trust” paper, for reasons Schneier explains.
Prompt injection isn’t just a minor security problem we need to deal with. It’s a fundamental property of current LLM technology. The systems have no ability to separate trusted commands from untrusted data, and there are an infinite number of prompt injection attacks with no way to block them as a class. We need some new fundamental science of LLMs before we can solve this.
My layman’s understanding of the problem is this (actual AI experts, feel free to correct this paraphrase): A key ingredient that makes current LLMs so successful is that they treat all inputs uniformly. It’s fairly well known now that LLMs treat the system prompt and the user prompt the same, so they can’t tell when attackers poison the prompt. But LLMs also don’t distinguish when they inhale the world’s information via their training sets: LLM training treats high-quality papers and conspiracy theories and social media rants and fiction and malicious poisoned input the same, so they can’t tell when attackers try to poison the training data (such as by leaving malicious content around that they know will be scraped; see below).
So treating all input uniformly is LLMs’ superpower… but it also makes it hard to weed out bad or malicious inputs, because to start distinguishing inputs is to bend or break the core “special sauce” that makes current LLMs work so well.
This week, Schneier posted a new article about how AI’s security risks are amplified by agentic AI: “Agentic AI’s OODA Loop Problem.” Quoting a few key parts:
In 2022, Simon Willison identified a new class of attacks against AI systems: “prompt injection.” Prompt injection is possible because an AI mixes untrusted inputs with trusted instructions and then confuses one for the other. Willison’s insight was that this isn’t just a filtering problem; it’s architectural. There is no privilege separation, and there is no separation between the data and control paths. The very mechanism that makes modern AI powerful—treating all inputs uniformly—is what makes it vulnerable.
… A single poisoned piece of training data can affect millions of downstream applications.
… Attackers can poison a model’s training data and then deploy an exploit years later. Integrity violations are frozen in the model.
… Agents compound the risks. Pretrained OODA loops running in one or a dozen AI agents inherit all of these upstream compromises. Model Context Protocol (MCP) and similar systems that allow AI to use tools create their own vulnerabilities that interact with each other. Each tool has its own OODA loop, which nests, interleaves, and races. Tool descriptions become injection vectors. Models can’t verify tool semantics, only syntax. “Submit SQL query” might mean “exfiltrate database” because an agent can be corrupted in prompts, training data, or tool definitions to do what the attacker wants. The abstraction layer itself can be adversarial.
For example, an attacker might want AI agents to leak all the secret keys that the AI knows to the attacker, who might have a collector running in bulletproof hosting in a poorly regulated jurisdiction. They could plant coded instructions in easily scraped web content, waiting for the next AI training set to include it. Once that happens, they can activate the behavior through the front door: tricking AI agents (think a lowly chatbot or an analytics engine or a coding bot or anything in between) that are increasingly taking their own actions, in an OODA loop, using untrustworthy input from a third-party user. This compromise persists in the conversation history and cached responses, spreading to multiple future interactions and even to other AI agents.
… Prompt injection might be unsolvable in today’s LLMs. … More generally, existing mechanisms to improve models won’t help protect against attack. Fine-tuning preserves backdoors. Reinforcement learning with human feedback adds human preferences without removing model biases. Each training phase compounds prior compromises.
This is Ken Thompson’s “trusting trust” attack all over again.
Thompson’s Turing Award lecture “Reflections on Trusting Trust” is a must-read classic, and super short: just three pages. If you haven’t read it lately, run (don’t walk) and reread it on your next coffee break.
I love AI and LLMs. I use them every day. I look forward to letting an AI generate and commit more code on my behalf, just not quite yet — I’ll wait until the AI wizards deliver new generations of LLMs with improved architectures that let the defenders catch up again in the security arms race. I’m sure they’ll get there, and that’s just what we need to keep making the wonderful AIs we now enjoy also be trustworthy to deploy in more and more ways.
A lotof this EO is repeating the same things I urged in my essay nearly a year ago, “C++ safety — in context”… here’s a cut-and-paste of my “Call(s) to action” conclusion section I published back then, and I think you’ll see a heavy overlap with this week’s new EO…
Call(s) to action
As an industry generally, we must make a major improvement in programming language memory safety — and we will.
In C++ specifically, we should first target the four key safety categories that are our perennial empirical attack points (type, bounds, initialization, and lifetime safety), and drive vulnerabilities in these four areas down to the noise for new/updated C++ code — and we can.
But we must also recognize that programming language safety is not a silver bullet to achieve cybersecurity and software safety. It’s one battle (not even the biggest) in a long war: Whenever we harden one part of our systems and make that more expensive to attack, attackers always switch to the next slowest animal in the herd. Many of 2023’s worst data breaches did not involve malware, but were caused by inadequately stored credentials (e.g., Kubernetes Secrets on public GitHub repos), misconfigured servers (e.g., DarkBeam, Kid Security), lack of testing, supply chain vulnerabilities, social engineering, and other problems that are independent of programming languages. Apple’s white paper about 2023’s rise in cybercrime emphasizes improving the handling, not of program code, but of the data: “it’s imperative that organizations consider limiting the amount of personal data they store in readable format while making a greater effort to protect the sensitive consumer data that they do store [including by using] end-to-end [E2E] encryption.”
No matter what programming language we use, security hygiene is essential:
Do use your language’s static analyzers and sanitizers. Never pretend using static analyzers and sanitizers is unnecessary “because I’m using a safe language.” If you’re using C++, Go, or Rust, then use those languages’ supported analyzers and sanitizers. If you’re a manager, don’t allow your product to be shipped without using these tools. (Again: This doesn’t mean running all sanitizers all the time; some sanitizers conflict and so can’t be used at the same time, some are expensive and so should be used periodically, and some should be run only in testing and never in production including because their presence can create new security vulnerabilities.)
Do keep all your tools updated. Regular patching is not just for iOS and Windows, but also for your compilers, libraries, and IDEs.
Do secure your software supply chain. Do use package management for library dependencies. Do track a software bill of materials for your projects.
Don’t store secrets in code. (Or, for goodness’ sake, on GitHub!)
Do configure your servers correctly, especially public Internet-facing ones. (Turn authentication on! Change the default password!)
Do keep non-public data encrypted, both when at rest (on disk) and when in motion (ideally E2E… and oppose proposed legislation that tries to neuter E2E encryption with ‘backdoors only good guys will use’ because there’s no such thing).
Do keep investing long-term in keeping your threat modeling current, so that you can stay adaptive as your adversaries keep trying different attack methods.
We need to improve software security and software safety across the industry, especially by improving programming language safety in C and C++, and in C++ a 98% improvement in the four most common problem areas is achievable in the medium term. But if we focus on programming language safety alone, we may find ourselves fighting yesterday’s war and missing larger past and future security dangers that affect software written in any language.
Sadly, there are too many bad actors. For the foreseeable future, our software and data will continue to be under attack, written in any language and stored anywhere. But we can defend our programs and systems, and we will.
(*) My main disappointment is that some of the provisions have deadlines that are too far away. Specifically: Why would it take until 2030 to migrate to TLS 1.3? It’s not just more secure, it’s also faster and has been published for seven years already… maybe I’m just not aware enough of TLS 1.3 adoptability issues though, as I’m not a TLS expert.
(**) Here in the United States, we’ll have to see whether the incoming administration will continue this EO, or amend/replace/countermand it. In the United States, that’s a drawback of using an EO compared to passing an actual law with Congressional approval… an EO is “quick” because the President can issue it without getting legislative approval (for things that are in the Presidential remit), but for the same reason an EO also isn’t “durable” or guaranteed to outlive its administration. Because the next President can just order something different, an EO’s default shelf life is just 1-4 years.
So far, all the major U.S. cybersecurity EOs that could affect C++ have been issued since 2021, which means so far they have all come from one President… and so we’re all going to learn a lot this year, one way or another, about their permanence. (In both the U.S. and the E.U., actual laws are also in progress to shift software liability from consumer to software producers, and those will have real teeth. But here we’re talking about the U.S. EOs from 2021 to date.)
That said, what I see in these EOs is common sense pragmatism that’s forcing the software industry to eat our vegetables, so I’m cautiously optimistic that we’ll continue to maintain something like these EOs and build on them further as we continue to work hard to secure the infrastructure that our comfortable free lifestyle (and, possibly someday, our lives) depends on. This isn’t about whether we love a given programming language, it’s about how we can achieve the greatest hardening at the greatest possible scale for our civilization’s infrastructure, and for those of us whose remit includes the C++ language that means doing everything we can to harden as much of the existing C and C++ code out there as possible — all the programmers in the world can only write so much new/rewritten code every year, and for us in C++ by far the maximum contribution we can make to overall security issues related to programming languages (i.e., the subset of security issues that fall into our remit) is to find ways to improve existing C and C++ code with no manual source code changes — that won’t always be possible, but where it’s possible it will maximize our effectiveness in improving security at enormous scale. See also this 2-minute answer I gave in post-talk Q&A in Poland two months ago.
Next week, on January 15, I’ll be speaking at the University of Waterloo, my alma mater. There’ll be a tech talk on key developments in C++ and why I think the language’s future over the next decade will be exciting, with lots of time allocated to a “fireside chat / interview” session for Q&A. The session is hosted by Waterloo’s Women in Computer Science (WiCS) group, and dinner and swag by Citadel Securities, where I work.
This talk is open to Waterloo students only (registration required). The organizers are arranging an option to watch remotely for the half of you who are away from campus on your co-op work terms right now — I vividly remember those! Co-op is a great experience.
I look forward to meeting many current students next week, and comparing notes about co-op work terms, pink ties (I still have mine) and MathSoc and C&D food (if Math is your faculty), WATSFIC, and “Water∞loo” jokes (I realize doing this in January is tempting the weather/travel gods, but I do know how to drive in snow…).
Two weeks ago, Bjarne and I and lots of ISO committee members had a blast at the code::dive C++ conference held on November 25, just two days after the end of the Wrocław ISO C++ meeting. Thanks again to Nokia for hosting the ISO meeting, and for inviting us all to speak at their conference! My talk was an updated-and-shortened version of my CppCon keynote (which I also gave at Meeting C++; I’ll post a link to that video too once it’s posted):
If you already saw the CppCon talk, you can skip to these “new parts at the end” where the Q&A got into very interesting topics:
That morning, on our route while traveling from the hotel to the conference site, at one point we noticed that up ahead there was a long line of people all down the length of a block and wrapped around the corner. It took me a few beats to realize that was where we were going, and those were the people still waiting to get in to the conference (at that time there were already over 1,000 people inside the building). Here’s one photo that appeared in the local news showing part of the queue:
In all, I’m told 1,800 people attended on-site, and 8,000 attended online. Thank you again to our Nokia hosts for hosting the ISO C++ meeting and inviting us to code::dive, and thank you to all the C++ developers (and, I’m sure, a few C++-curious) who came from Poland and beyond to spend a day together talking about our favorite programming language!
(*) Here’s a transcript of what I said in that closing summary:
… Reflection and safety improvements as what I see are the two big drivers of our next decade of C++.
So I’m excited about C++. I really think that this was a turning point year, because we’ve been talking about safety for a decade, the Core Guidelines are a decade old, we’ve been talking about reflection for 20 years in the C++ committee — but this is the year that it’s starting to get real. This is the year we put erroneous behavior [in] and eliminated uninitialized locals in the standard, this is the year that we design-approved reflection for the standard — both for C++26 and hopefully they’ll both get in. We are starting to finally see these proposals land, and this is going to create a beautiful new decade, open up a new fresh era of C++. Bjarne [….] when C++11 came out, he said, you know, there’s been so many usability improvements here that C++11, even though it’s fully compatible with C++98, it feels like a new language. I think we’re about to do that again, and to make C++26 feel like a new language. And then just as we built on C++11 and finished it with C++14, 17, 20, the same thing with this generation. That’s how I view it. I’m very hopeful for a bright future for C++. Our language and our community continues to grow, and it’s great to see us addressing the problems we most need to address, so we have an answer for safety, we have an answer for simpler build systems and reducing the number of side languages to make C++ work in practice. And I’m looking forward to the ride for the next decade and more.
And at the end of the Q&A, the final part of my answer about why I’m focused on C++ rather than other efforts:
Why am I spending all this time in ISO C++? Not just because I’m some C++-lover on a fanatical level — you may accuse me of that too — but it’s just because I want to have an impact. I’m a user of this world’s society and civilization. I use this world’s banking system. I rely on this world’s hospital system. I rely on this world’s power grid. And darnit I don’t want that compromised, I want to harden it against attack. And if I put all my energy into some new programming language, I will have some impact, but it’s going to be much smaller because I can only write so much new code. If I can find a way to just recompile — that’s why you keep hearing me say that — to just recompile the billions of lines of C++ code that exist today, and make them even 10% safer, and I hope to make them much more than that safer, I will have had an outsized effect on securing our civilization. And I don’t mean to speak too grandiosely, but look at all the C++ code that needs fixing. If you can find a way to do that, it will have an outsized impact and benefit to society. And that’s why I think it’s important, because C++ is important — and not leaving all that code behind, helping that code too as well as new code, I think is super important, and that’s kind of my motivation.
Starting today I’m excited to be working on a new team, with my C++ standards and community roles unchanged. I also wanted to write a few words about why I’m excited about continuing to invest my time heavily in C++’s standardization and evolution especially now, because I think 2024 has been a pivotal year for C++ — and so this has turned into a bit of an early “year-end C++ retrospective” post too.
It’s been a blast to be on the Microsoft Visual C++ compiler team for over 22 years! The time has flown by because the people and the challenges have always been world-class. An underappreciated benefit of being on a team that owns a foundational technology (like a major C++ compiler) is that you often don’t have to change teams to find interesting projects, because new interesting projects need compiler support and so tend to come to you. That’s been a real privilege, and why I stuck around way longer than any other job I’ve held. Now I am finally going to switch to a new job, but I’ll continue to cheer my colleagues on as a happy MSVC user on my own projects, consuming all the cool things they’re going to do next!
Today I’m thrilled to start at Citadel Securities, a firm that “combines deep trading acumen with leading-edge analytics and technology to deliver liquidity to some of the world’s most important markets, retail brokerages, and financial institutions.” I’ve known folks at CitSec for many years now (including some who participate in WG 21) and have long known it to be a great organization with some of the brightest minds in engineering and beyond. Now I’m looking forward to helping to drive CitSec’s internal C++ training initiatives, advise on technical strategy, share things I’ve learned along the way about sound design for both usability and pragmatic adoptability, and mentor a new set of talented folks there to not only take their own skilled next steps but also to themselves become mentors to others in turn. I think a continuous growth and learning culture like I’ve seen at CitSec consistently for over a dozen years is one of the most important qualities a company can have, because if you have that you can always grow all the other things you need, including as demands evolve over time. But maybe most of all I’m looking forward to learning a lot myself as I dive back into the world of finance — finance is where I started my junior career in the 80s and 90s, and I’m sure I’ll learn a ton in CitSec’s diverse set of 21st-century businesses that encounter interesting, leading-edge technical challenges every day that go well beyond the ones I encountered back in the 20th.
My other C++ community roles are unchanged — I’m continuing my current term as chair of the ISO C++ committee, I’m continuing as chair of the Standard C++ Foundation, and especially I’m continuing to work heavily on ISO C++ evolution (I have eight papers in the current mailing for this month’s Wrocław meeting!) including supporting those with cppfront prototype implementations. I meant it when I said in my CppCon talk that C++’s next decade will be dominated by reflection and safety improvements, and that C++26 really is shaping up to be the most impactful release since C++11 that started a new era of C++; it’s an exciting time for C++ and I plan to keep spending a lot of time contributing to C++26 and beyond.
Drilling down a little: Why is 2024 a pivotal year for C++? Because for the first time in 2024 the ISO committee has started adopting (or is on track to soon adopt) serious safety and reflection improvements into the draft C++ standard, and that’s a big turning point:
For safety: With uninitialized local variables no longer being undefined behavior (UB) in C++26 as of March 2024, C++ is taking a first serious step to really removing safety-related UB, and achieve the ‘holy grail’ of an easy adoption story: “Just recompile your existing code with a C++26 compiler, with zero manual code changes, and it’s safer with less UB.” This month, I’m following up on that proposing P3436R1, a strategy for how we could remove all safety-related UB by default from C++ — something that I’m pretty sure a lot of folks can’t imagine C++ could ever do while still remaining true to what makes C++ be C++, but that in fact C++ has already been doing for years in constexpr code! The idea I’m proposing is to remove the same cases of UB we already do in constexpr code also at execution time, in one of two ways for each case: when it’s efficient enough, eliminate that case universally the same as we just did for uninitialized locals; otherwise, leverage the great ideas in the Profiles proposals as a way to opt in/out of that case (see P3436 for details). If the committee likes the idea enough to encourage me to go do more work to flesh it out, over the winter I’ll invest the time to expand the paper into a complete catalog of safety-related UB with a per-case proposal to eliminate that UB at execution time. If we can really achieve a future C++ where you can “just recompile your existing code with safety Profiles enabled, and it’s safer with zero safety-related UB,” that would be a huge step forward. (Of course, some Profiles rules will require code changes to get the full safety benefits; see the details in section 2 of my supporting Profiles paper.)
For reflection: Starting with P2996R7 whose language part was design-approved for C++26 in June 2024, we can lay a foundation to then build on with follow-on papers like P3294R2 and P3437R1 to add generation and more features. As I demonstrated with examples in the above-linked CppCon talk, reflection (including generation) will be a game-changer that I believe will dominate the next decade of C++ as we build it out in the standard and learn to use it in the global C++ community. I’m working with P2996/P3294 prototypes and my own cppfront compiler to help gather usability experience, and I’m contributing my papers like P0707R5 and P3437R1 as companion/supporting papers to those core proposals to try to help them progress.
As Bjarne Stroustrup famously said, “C++11 [felt] like a new language,” starting a new “modern” C++ style featuring auto and lambdas and standard safe smart pointers and range-for and move semantics and constexpr compile-time code, that we completed and built on over the next decade with C++14/17/20/23. (And don’t forget that C++11’s move semantics already delivered the ideal adoption story of “just recompile your existing code with a C++11 compiler, with zero manual code changes, and it’s faster.”) Since 2011 until now, “modern C++” has pretty much meant “C++ since C++11” because C++11 made that much of a difference in how C++ worked and felt.
Now I think C++26 is setting the stage to do that again for a second time: Our next major era of what “modern C++” will mean will be characterized by having safety by default and first-class support for reflection-based generative compile-time libraries. Needless to say, this is a group effort that is accomplished only by an amazing set of C++ pros from dozens of countries, including the authors of the above papers but also many hundreds of other experts who help design and review features. To all of those experts: Again, thank you! I’ll keep trying to contribute what I can too, to help ship C++26 with its “version 1” of a set of these major new foundational tools and to continue to add to that foundation further in the coming years as we all learn to use the new features to make our code safer and simpler.
C++ is critically important to our society, and is right now actively flourishing. C++ is essential not only at Citadel Securities itself, but throughout capital markets and the financial industry… and even that is itself just one of the critical sectors of our civilization that heavily depend on C++ code and will for the foreseeable future. I’m thrilled that CitSec’s leadership shares my view of that, and my same goals for continuing to evolve ISO C++ to make it better, especially when it comes to increasing safety and usability to harden our society’s key infrastructure (including our markets) and to make C++ even easier to use and more expressive. I’m excited to see what the coming decade of C++ brings… 2024 really has shaped up to be a pivotal year for C++ evolution, and I can’t wait to see where the ride takes us next.
Scope. To talk about C++’s current safety problems and solutions well, I need to include the context of the broad landscape of security and safety threats facing all software. I chair the ISO C++ standards committee and I work for Microsoft, but these are my personal opinions and I hope they will invite more dialog across programming language and security communities.
Acknowledgments. Many thanks to people from the C, C++, C#, Python, Rust, MITRE, and other language and security communities whose feedback on drafts of this material has been invaluable, including: Jean-François Bastien, Joe Bialek, Andrew Lilley Brinker, Jonathan Caves, Gabriel Dos Reis, Daniel Frampton, Tanveer Gani, Daniel Griffing, Russell Hadley, Mark Hall, Tom Honermann, Michael Howard, Marian Luparu, Ulzii Luvsanbat, Rico Mariani, Chris McKinsey, Bogdan Mihalcea, Roger Orr, Robert Seacord, Bjarne Stroustrup, Mads Torgersen, Guido van Rossum, Roy Williams, Michael Wong.
Terminology (see ISO/IEC 23643:2020). “Software security” (or “cybersecurity” or similar) means making software able to protect its assets from a malicious attacker. “Software safety” (or “life safety” or similar) means making software free from unacceptable risk of causing unintended harm to humans, property, or the environment. “Programming language safety” means a language’s (including its standard libraries’) static and dynamic guarantees, including but not limited to type and memory safety, which helps us make our software both more secure and more safe. When I say “safety” unqualified here, I mean programming language safety, which benefits both software security and software safety.
We must make our software infrastructure more secure against the rise in cyberattacks (such as on power grids, hospitals, and banks), and safer against accidental failures with the increased use of software in life-critical systems (such as autonomous vehicles and autonomous weapons).
The past two years in particular have seen extra attention on programming language safety as a way to help build more-secure and -safe software; on the real benefits of memory-safe languages (MSLs); and that C and C++ language safety needs to improve — I agree.
But there have been misconceptions, too, including focusing too narrowly on programming language safety as our industry’s primary security and safety problem — it isn’t. Many of the most damaging recent security breaches happened to code written in MSLs (e.g., Log4j) or had nothing to do with programming languages (e.g., Kubernetes Secrets stored on public GitHub repos).
In that context, I’ll focus on C++ and try to:
highlight what needs attention (what C++’s problem “is”), and how we can get there by building on solutions already underway;
address some common misconceptions (what C++’s problem “isn’t”), including practical considerations of MSLs; and
leave a call to action for programmers using all languages.
tl;dr: I don’t want C++ to limit what I can express efficiently. I just want C++ to let me enforce our already-well-known safety rules and best practices by default, and make me opt out explicitly if that’s what I want. Then I can still use fully modern C++… just nicer.
Let’s dig in.
The immediate problem “is” that it’s Too Easy By Default™ to write security and safety vulnerabilities in C++ that would have been caught by stricter enforcement of known rules for type, bounds, initialization, and lifetime language safety
In C++, we need to start with improving these four categories. These are the main four sources of improvement provided by all the MSLs that NIST/NSA/CISA/etc. recommend using instead of C++ (example), so by definition addressing these four would address the immediate NIST/NSA/CISA/etc. issues with C++. (More on this under “The problem ‘isn’t’… (1)” below.)
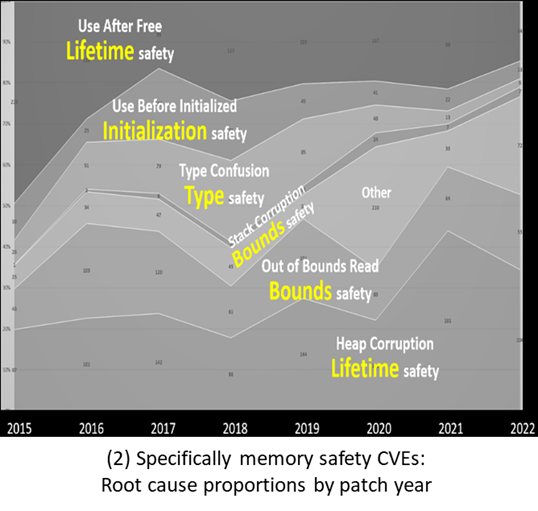
And in all recent years including 2023 (see figures 1’s four highlighted rows, and figure 2), these four constitute the bulk of those oft-quoted 70% of CVEs (Common [Security] Vulnerabilities and Exposures) related to language memory unsafety. (However, that “70% of language memory unsafety CVEs” is misleading; for example, in figure 1, most of MITRE’s 2023 “most dangerous weaknesses” did not involve language safety and so are outside that denominator. More on this under “The problem ‘isn’t’… (3)” below.)
The C++ guidance literature already broadly agrees on safety rules in those categories. It’s true that there is some conflicting guidance literature, particularly in environments that ban exceptions or run-time type support and so use some alternative rules. But there is consensus on core safety rules, such as banning unsafe casts, uninitialized variables, and out-of-bounds accesses (see Appendix).
C++ should provide a way to enforce them by default, and require explicit opt-out where needed. We can and do write “good” code and secure applications in C++. But it’s easy even for experienced C++ developers to accidentally write “bad” code and security vulnerabilities that C++ silently accepts, and that would be rejected as safety violations in other languages. We need the standard language to help more by enforcing the known best practices, rather than relying on additional nonstandard tools to recommend them.
These are not the only four aspects of language safety we should address. They are just the immediate ones, a set of clear low-hanging fruit where there is both a clear need and clear way to improve (see Appendix).
Note: And safety categories are of course interrelated. For example, full type safety (that an accessed object is a valid object of its type) requires eliminating out-of-bounds accesses to unallocated objects. But, conversely, full bounds safety (that accessed memory is inside allocated bounds) similarly requires eliminating type-unsafe downcasts to larger derived-type objects that would appear to extend beyond the actual allocation.
Software safety is also important. Cyberattacks are urgent, so it’s natural that recent discussions have focused more on security and CVEs first. But as we specify and evolve default language safety rules, we must also include our stakeholders who care deeply about functional safety issues that are not reflected in the major CVE buckets but are just as harmful to life and property when left in code. Programming language safety helps both software security and software safety, and we should start somewhere, so let’s start (but not end) with the known pain points of security CVEs.
In those four buckets, a 10-50x improvement (90-98% reduction) is sufficient
If there were 90-98% fewer C++ type/bounds/initialization/lifetime vulnerabilities we wouldn’t be having this discussion. All languages have CVEs, C++ just has more (and C still more). [Updated: Removed count of 2024 Rust vs C/C++ CVEs because MITRE.org search doesn’t have a great way of accurately counting the latter.] So zero isn’t the goal; something like a 90% reduction is necessary, and a 98% reduction is sufficient, to achieve security parity with the levels of language safety provided by MSLs… and has the strong benefit that I believe it can be achieved with perfect backward link compatibility (i.e., without changing C++’s object model, and its lifetime model which does not depend on universal tracing garbage collection and is not limited to tree-based data structures) which is essential to our being able to adopt the improvements in existing C++ projects as easily as we can adopt other new editions of C++. — After that, we can pursue additional improvements to other buckets, such as thread safety and overflow safety.
Aiming for 100%, or zero CVEs in those four buckets, would be a mistake:
100% is not necessary because none of the MSLs we’re being told to use instead are there either. More on this in “The problem ‘isn’t’… (2)” below.
100% is not sufficient because many cyberattacks exploit security weaknesses other than memory safety.
And getting that last 2% would be too costly, because it would require giving up on link compatibility and seamless interoperability (or “interop”) with today’s C++ code. For example, Rust’s object model and borrow checker deliver great guarantees, but require fundamental incompatibility with C++ and so make interop hard beyond the usual C interop level. One reason is that Rust’s safe language pointers are limited to expressing tree-shaped data structures that have no cycles; that unique ownership is essential to having great language-enforced aliasing guarantees, but it also requires programmers to use ‘something else’ for anything more complex than a tree (e.g., using Rc, or using integer indexes as ersatz pointers); it’s not just about linked lists but those are a simple well-known illustrative example.
If we can get a 98% improvement and still have fully compatible interop with existing C++, that would be a holy grail worth serious investment.
A 98% reduction across those four categories is achievable in new/updated C++ code, and partially in existing code
Since at least 2014, Bjarne Stroustrup has advocated addressing safety in C++ via a “subset of a superset”: That is, first “superset” to add essential items not available in C++14, then “subset” to exclude the unsafe constructs that now all have replacements.
As of C++20, I believe we have achieved the “superset,” notably by standardizing span, string_view, concepts, and bounds-aware ranges. We may still want a handful more features, such as a null-terminated zstring_view, but the major additions already exist.
Now we should “subset”: Enable C++ programmers to enforce best practices around type and memory safety, by default, in new code and code they can update to conform to the subset. Enabling safety rules by default would not limit the language’s power but would require explicit opt-outs for non-standard practices, thereby reducing inadvertent risks. And it could be evolved over time, which is important because C++ is a living language and adversaries will keep changing their attacks.
ISO C++ evolution is already pursuing Safety Profiles for C++. The suggestions in the Appendix are refinements to that, to demonstrate specific enforcements and to try to maximize their adoptability and useful impact. For example, everyone agrees that many safety bugs will require code changes to fix. However, how many safety bugs could be fixed without manual source code changes, so that just recompiling existing code with safety profiles enabled delivers some safety benefits? For example, we could by default inject a call-site bounds check 0 <= b < a.size() on every subscript expression a[b] when a.size() exists and a is a contiguous container, without requiring any source code changes and without upgrading to a new internally bounds-checked container library; that checking would Just Work out of the box with every contiguous C++ standard container, span, string_view, and third-party custom container with no library updates needed (including therefore also no concern about ABI breakage).
Rules like those summarized in the Appendix would have prevented (at compile time, test time or run time) most of the past CVEs I’ve reviewed in the type, bounds, and initialization categories, and would have prevented many of the lifetime CVEs. I estimate a roughly 98% reduction in those categories is achievable in a well-defined and standardized way for C++ to enable safety rules by default, while still retaining perfect backward link compatibility. See the Appendix for a more detailed description.
We can and should emphasize adoptability and benefit also for C++ code that cannot easily be changed. Any code change to conform to safety rules carries a cost; worse, not all code can be easily updated to conform to safety rules (e.g., it’s old and not understood, it belongs to a third party that won’t allow updates, it belongs to a shared project that won’t take upstream changes and can’t easily be forked). That’s why above (and in the Appendix) I stress that C++ should seriously try to deliver as many of the safety improvements as practical without requiring manual source code changes, notably by automatically making existing code do the right thing when that is clear (e.g., the bounds checks mentioned above, or emitting static_cast pointer downcasts as effectively dynamic_cast without requiring the code to be changed), and by offering automated fixits that the programmer can choose to apply (e.g., to change the source for static_cast pointer downcasts to actually say dynamic_cast). Even though in many cases a programmer will need to thoughtfully update code to replace inherently unsafe constructs that can’t be automatically fixed, I believe for some percentage of cases we can deliver safety improvements by just recompiling existing code in the safety-rules-by-default mode, and we should try because it’s essential to maximizing safety profiles’ adoptability and impact.
What the problem “isn’t”: Some common misconceptions
(1) The problem “isn’t” defining what we mean by “C++’s most urgent language safety problem.” We know the four kinds of safety that most urgently need to be improved: type, bounds, initialization, and lifetime safety.
We know these four are the low-hanging fruit (see “The problem ‘is’…” above). It’s true that these are just four of perhaps two dozen kinds of “safety” categories, including ones like safe integer arithmetic. But:
Most of the others are either much smaller sources of problems, or are primarily important because they contribute to those four main categories. For example, the integer overflows we care most about are indexes and sizes, which fall under bounds safety.
Most MSLs don’t address making these safe by default either, typically due to the checking cost. But all languages (including C++) usually have libraries and tools to address them. For example, Microsoft ships a SafeInt library for C++ to handle integer overflows, which is opt-in. C# has a checked arithmetic language feature to handle integer overflows, which is opt-in. Python’s built-in integers are overflow-safe by default because they automatically expand; however, the popular NumPy fixed-size integer types do not check for overflow by default and require using checked functions, which is opt-in.
Thread safety is obviously important too, and I’m not ignoring it. I’m just pointing out that it is not one of the top target buckets: Most of the MSLs that NIST/NSA/CISA/etc. recommend over C++ (except uniquely Rust, and to a lesser extent Python) address thread safety impact on userdata corruption about as well as C++. The main improvement MSLs give is that a program data race will not corrupt the language’s own virtual machine (whereas in C++ a data race is currently all-bets-are-off undefined behavior). Some languages do give some additional protection, such as that Python guarantees two racing threads cannot see a torn write of an integer and reduces other possible interleavings because of the global interpreter lock (GIL).
(2) The problem “isn’t” that C++ code is not formally provably safe.
Yes, C++ code makes it too easy to write silently-unsafe code by default (see “The problem ‘is’…” above).
But I’ve seen some people claim we need to require languages to be formally provably safe, and that would be a bridge too far. Much to the chagrin of CS theorists, mainstream commercial programming languages aren’t formally provably safe. Consider some examples:
None of the widely-used languages we view as MSLs (except uniquely Rust) claim to be thread-safe and race-free by construction, as covered in the previous section. Yet we still call C#, Go, Java, Python, and similar languages “safe.” Therefore, formally guaranteeing thread safety properties can’t be a requirement to be considered a sufficiently safe language.
That’s because a language’s choice of safety guarantees is a tradeoff: For example, in Rust, safe code uses tree-based dynamic data structures only. This feature lets Rust deliver stronger thread safety guarantees than other safe languages, because it can more easily reason about and control aliasing. However, this same feature also requires Rust programs to use unsafe code more often to represent common data structures that do not require unsafe code to represent in other MSLs such as C# or Java, and so 30% to 50% of Rust crates use unsafe code, compared for example to 25% of Java libraries.
C#, Java, and other MSLs still have use-before-initialized and use-after-destroyed type safety problems too: They guarantee not accessing memory outside its allocated lifetime, but object lifetime is a subset of memory lifetime (objects are constructed after, and destroyed/disposed before, the raw memory is allocated and deallocated; before construction and after dispose, the memory is allocated but contains “raw bits” that likely don’t represent a valid object of its type). If you doubt, please run (don’t walk) and ask ChatGPT about Java and C# problems with: access-unconstructed-object bugs (e.g., in those languages, any virtual call in a constructor is “deep” and executes in a derived object before the derived object’s state is initialized); use-after-dispose bugs; “resurrection” bugs; and why those languages tell people never to use their finalizers. Yet these are great languages and we rightly consider them safe languages. Therefore, formally guaranteeing no-use-before-initialized and no-use-after-dispose can’t be a requirement to be considered a sufficiently safe language.
Rust, Go, and other languages support sanitizers too, including ThreadSanitizer and undefined behavior sanitizers, and related tools like fuzzers. Sanitizers are known to be still needed as a complement to language safety, and not only for when programmers use ‘unsafe’ code; furthermore, they go beyond finding memory safety issues. The uses of Rust at scale that I know of also enforce use of sanitizers. So using sanitizers can’t be an indicator that a language is unsafe — we should use the supported sanitizers for code written in any language.
Note: “Use your sanitizers” does not mean to use all of them all the time. Some sanitizers conflict with each other, so you can only use those one at a time. Some sanitizers are expensive, so they should only be run periodically. Some sanitizers should not be run in production, including because their presence can create new security vulnerabilities.
(3) The problem “isn’t” that moving the world’s C and C++ code to memory-safe languages (MSLs) would eliminate 70% of security vulnerabilities.
MSLs are wonderful! They just aren’t a silver bullet.
An oft-quoted number is that “70%” of programming language-caused CVEs (reported security vulnerabilities) in C and C++ code are due to language safety problems. That number is true and repeatable, but has been badly misinterpreted in the press: No security expert I know believes that if we could wave a magic wand and instantly transform all the world’s code to MSLs, that we’d have 70% fewer CVEs, data breaches, and ransomware attacks. (For example, see this February 2024 example analysis paper.)
Consider some reasons.
That 70% is of the subset of security CVEs that can be addressed by programming language safety. See figure 1 again: Most of 2023’s top 10 “most dangerous software weaknesses” were not related to memory safety. Many of 2023’s largest data breaches and other cyberattacks and cybercrime had nothing to do with programming languages at all. In 2023, attackers reduced their use of malware because software is getting hardened and endpoint protection is effective (CRN), and attackers go after the slowest animal in the herd. Most of the issues listed in NISTIR-8397 affect all languages equally, as they go beyond memory safety (e.g., Log4j) or even programming languages (e.g., automated testing, hardcoded secrets, enabling OS protections, string/SQL injections, software bills of materials). For more detail see the Microsoft response to NISTIR-8397, for which I was the editor. (More on this in the Call to Action.)
MSLs get CVEs too, though definitely fewer (again, e.g., Log4j). For example, see MITRE list of Rust CVEs, including six so far in 2024. And all programs use unsafe code; for example, see the Conclusions section of Firouzi et al.’s study of uses of C#’s unsafe on StackOverflow and prevalence of vulnerabilities, and that all programs eventually call trusted native libraries or operating system code.
Saying the quiet part out loud: CVEs are known to be an imprecise metric. We use it because it’s the metric we have, at least for security vulnerabilities, but we should use it with care. This may surprise you, as it did me, because we hear a lot about CVEs. But whenever I’ve suggested improvements for C++ and measuring “success” via a reduction in CVEs (including in this essay), security experts insist to me that CVEs aren’t a great metric to use… including the same experts who had previously quoted the 70% CVE number to me. — Reasons why CVEs aren’t a great metric include that CVEs are self-reported and often self-selected, and not all are equally exploitable; but there can be pressure to report a bug as a vulnerability even if there’s no reasonable exploit because of the benefits of getting one’s name on a CVE. In August 2023, the Python Software Foundation became a CVE Numbering Authority (CNA) for Python and pip distributions, and now has more control over Python and pip CVEs. The C++ community has not done so.
CVEs target only software security vulnerabilities (cyberattacks and intrusions), and we also need to consider software safety (life-critical systems and unintended harm to humans).
(4) The problem “isn’t” that C++ programmers aren’t trying hard enough / using the existing tools well enough. The challenge is making it easier to enable them.
Today, the mitigations and tools we do have for C++ code are an uneven mix, and all are off-by-default:
Kind. They are a mix of static tools, dynamic tools, compiler switches, libraries, and language features.
Acquisition. They are acquired in a mix of ways: in-the-box in the C++ compiler, optional downloads, third-party products, and some you need to google around to discover.
Accuracy. Existing rulesets mix rules with low and high false positives. The latter are effectively unadoptable by programmers, and their presence makes it difficult to “just adopt this whole set of rules.”
Determinism. Some rules, such as ones that rely on interprocedural analysis of full call trees, are inherently nondeterministic (because an implementation gives up when fully evaluating a case exceeds the space and time available; a.k.a. “best effort” analysis). This means that two implementations of the identical rule can give different answers for identical code (and therefore nondeterministic rules are also not portable, see below).
Efficiency. Existing rulesets mix rules with low and high (and sometimes impossible) cost to diagnose. The rules that are not efficient enough to implement in the compiler will always be relegated to optional standalone tools.
Portability. Not all rules are supported by all vendors. “Conforms to ISO/IEC 14882 (Standard C++)” is the only thing every C++ tool vendor supports portably.
To address all these points, I think we need the C++ standard to specify a mode of well-agreed and low-or-zero-false-positive deterministic rules that are sufficiently low-cost to implement in-the-box at build time.
Call(s) to action
As an industry generally, we must make a major improvement in programming language memory safety — and we will.
In C++ specifically, we should first target the four key safety categories that are our perennial empirical attack points (type, bounds, initialization, and lifetime safety), and drive vulnerabilities in these four areas down to the noise for new/updated C++ code — and we can.
But we must also recognize that programming language safety is not a silver bullet to achieve cybersecurity and software safety. It’s one battle (not even the biggest) in a long war: Whenever we harden one part of our systems and make that more expensive to attack, attackers always switch to the next slowest animal in the herd. Many of 2023’s worst data breaches did not involve malware, but were caused by inadequately stored credentials (e.g., Kubernetes Secrets on public GitHub repos), misconfigured servers (e.g., DarkBeam, Kid Security), lack of testing, supply chain vulnerabilities, social engineering, and other problems that are independent of programming languages. Apple’s white paper about 2023’s rise in cybercrime emphasizes improving the handling, not of program code, but of the data: “it’s imperative that organizations consider limiting the amount of personal data they store in readable format while making a greater effort to protect the sensitive consumer data that they do store [including by using] end-to-end [E2E] encryption.”
No matter what programming language we use, security hygiene is essential:
Do use your language’s static analyzers and sanitizers. Never pretend using static analyzers and sanitizers is unnecessary “because I’m using a safe language.” If you’re using C++, Go, or Rust, then use those languages’ supported analyzers and sanitizers. If you’re a manager, don’t allow your product to be shipped without using these tools. (Again: This doesn’t mean running all sanitizers all the time; some sanitizers conflict and so can’t be used at the same time, some are expensive and so should be used periodically, and some should be run only in testing and never in production including because their presence can create new security vulnerabilities.)
Do keep all your tools updated. Regular patching is not just for iOS and Windows, but also for your compilers, libraries, and IDEs.
Do secure your software supply chain. Do use package management for library dependencies. Do track a software bill of materials for your projects.
Don’t store secrets in code. (Or, for goodness’ sake, on GitHub!)
Do configure your servers correctly, especially public Internet-facing ones. (Turn authentication on! Change the default password!)
Do keep non-public data encrypted, both when at rest (on disk) and when in motion (ideally E2E… and oppose proposed legislation that tries to neuter E2E encryption with ‘backdoors only good guys will use’ because there’s no such thing).
Do keep investing long-term in keeping your threat modeling current, so that you can stay adaptive as your adversaries keep trying different attack methods.
We need to improve software security and software safety across the industry, especially by improving programming language safety in C and C++, and in C++ a 98% improvement in the four most common problem areas is achievable in the medium term. But if we focus on programming language safety alone, we may find ourselves fighting yesterday’s war and missing larger past and future security dangers that affect software written in any language.
Sadly, there are too many bad actors. For the foreseeable future, our software and data will continue to be under attack, written in any language and stored anywhere. But we can defend our programs and systems, and we will.
Be well, and may we all keep working to have a safer and more secure 2024.
Appendix: Illustrating why a 98% reduction is feasible
This Appendix exists to support why I think a 98% reduction in type/bounds/initialization/lifetime CVEs in C++ code is believable. This is not a formal proposal, but an overview of concrete ways to achieve such an improvement it in new and updatable code, and ways to even get some fraction of that improvement in existing code we cannot update but can recompile. These notes are aligned with the proposals currently being pursued in the ISO C++ safety subgroup, and if they pan out as I expect in ongoing discussions and experiments, then I intend to write further details about them in a future paper.
There are runtime and code size overheads to some of the suggestions in all four buckets, notably checking bounds and casts. But there is no reason to think those overheads need to be inherently worse in C++ than other languages, and we can make them on by default and still provide a way to opt out to regain full performance where needed.
Note: For example, bounds checking can cause a major impact on some hot loops, when using a compiler whose optimizer does not hoist bounds checks; not only can the loops incur redundant checking, but they also may not get other optimizations such as not being vectorized. This is why making bounds-checking on by default is good, but all performance-oriented languages also need to provide a way to say “trust me” and explicitly opt out of bounds checking tactically where needed.
The best way for “how” to let the programmer control enabling those rules (e.g., via source code annotations, compiler switches, and/or something else) is an orthogonal UX issue that is now being actively discussed in the C++ standards committee and community.
Type safety
Enforce the Pro.Type safety profile by default. That includes either banning or checking all unsafe casts and conversions (e.g., static_cast pointer downcasts, reinterpret_cast), including implicit unsafe type punning via C union and vararg.
However, these rules haven’t yet been systematically enforced in the industry. For example, in recent years I’ve painfully observed a significant set of type safety-caused security vulnerabilities whose root cause was that code used static_cast instead of dynamic_cast for pointer downcasts, and “C++” gets blamed even when the actual problem was failure to follow the well-publicized guidance to use the language’s existing safe recommended feature. It’s time for a standardized C++ mode that enforces these rules by default.
Note: On some platforms and for some applications, dynamic_cast has problematic space and time overheads that hinder its use. Many implementations bundle dynamic_cast indivisibly with all C++ run-time typing (RTTI) features (e.g., typeid), and so require storing full potentially-heavyweight RTTI data even though dynamic_cast needs only a small subset. Some implementations also use needlessly inefficient algorithms for dynamic_cast itself. So the standard must encourage (and, if possible, enforce for conformance, such as by setting algorithmic complexity requirements) that dynamic_cast implementations be more efficient and decoupled from other RTTI overheads, so that programmers do not have a legitimate performance reason not to use the safe feature. That decoupling could require an ABI break; if that is unacceptable, the standard must provide an alternative lightweight facility such as a fast_dynamic_cast that is separate from (other) RTTI and performs the dynamic cast with minimum space and time cost.
Bounds safety
Enforce the Pro.Bounds safety profile by default, and guarantee bounds checking. We should additionally guarantee that:
Pointer arithmetic is banned (use std::span instead); this enforces that a pointer refers to a single object. Array-to-pointer decay, if allowed, will point to only the first object in the array.
Only bounds-checked iterator arithmetic is allowed (also, prefer ranges instead).
All subscript operations are bounds-checked at the call site, by having the compiler inject an automatic subscript bounds check on every expression of the form a[b], where a is a contiguous sequence with a size/ssize function and b is an integral index. When a violation happens, the action taken can be customized using a global bounds violation handler; some programs will want to terminate (the default), others will want to log-and-continue, throw an exception, integrate with a project-specific critical fault infrastructure.
Importantly, the latter explicitly avoids implementing bounds-checking intrusively for each individual container/range/view type. Implementing bounds-checking non-intrusively and automatically at the call site makes full bounds checking available for every existing standard and user-written container/range/view type out of the box: Every subscript into a vector, span, deque, or similar existing type in third-party and company-internal libraries would be usable in checked mode without any need for a library upgrade.
It’s important to add automatic call-site checking now before libraries continue adding more subscript bounds checking in each library, so that we avoid duplicating checks at the call site and in the callee. As a counterexample, C# took many years to get rid of duplicate caller-and-callee checking, but succeeded and .NET Core addresses this better now; we can avoid most of that duplicate-check-elimination optimization work by offering automatic call-site checking sooner.
Language constructs like the range-for loop are already safe by construction and need no checks.
In cases where bounds checking incurs a performance impact, code can still explicitly opt out of the bounds check in just those paths to retain full performance and still have full bounds checking in the rest of the application.
Initialization safety
Enforce initialization-before-use by default. That’s pretty easy to statically guarantee, except for some cases of the unused parts of lazily constructed array/vector storage. Two simple alternatives we could enforce are (either is sufficient):
Initialize-at-declaration as required by Pro.Type and ES.20; and possibly zero-initialize data by default as currently proposed in P2723. These two are good but with some drawbacks; both have some performance costs for cases that require ‘dummy’ writes that are never used but hard for optimizers to eliminate, and the latter has some correctness costs because it ‘fixing’ some uninitialized cases where zero is a valid value but masks others for which zero is not a valid initializer and so the behavior is still wrong, but because a zero has been jammed in it’s harder for sanitizers to detect.
Guaranteed initialization-before-use, similar to what Ada and C# successfully do. This is still simple to use, but can be more efficient because it avoids the need for artificial ‘dummy’ writes, and can be more flexible because it allows alternative constructors to be used for the same object on different paths. For details, see: example diagnostic; definite-first-use rules.
Lifetime safety
Enforce the Pro.Lifetime safety profile by default, ban manual allocation by default, and guarantee null checking. The Lifetime profile is a static analysis that diagnoses many common sources of dangling and use-after-free, including for iterators and views (not just raw pointers and references), in a way that is efficient enough to run during compilation. It can be used as a basis to iterate on and further improve. And we should additionally guarantee that:
All manual memory management is banned by default (new, delete, malloc, and free). Corollary: ‘Owning’ raw pointers are banned by default, since they require delete or free. Use RAII instead, such as by calling make_unique or make_shared.
All dereferences are null-checked. The compiler injects an automatic check on every expression of the form *p or p-> where p can be compared to nullptr to null-check all dereferences at the call site (similar to bounds checks above). When a violation happens, the action taken can be customized using a global null violation handler; some programs will want to terminate (the default), others will want to log-and-continue, throw an exception, integrate with a project-specific critical fault infrastructure.
Note: The compiler could choose to not emit this check (and not perform optimizations that benefit from the check) when targeting platforms that already trap null dereferences, such as platforms that mark low memory pages as unaddressable. Some C++ features, such as delete, have always done call-site null checking.
Reducing undefined behavior and semantic bugs
Tactically, reduce some undefined behavior (UB) and other semantic bugs (pitfalls), for cases where we can automatically diagnose or even fix well-known antipatterns. Not all UB is bad; any performance-oriented language needs some. But we know there is low-hanging fruit where the programmer’s intent is clear and any UB or pitfall is a definite bug, so we can do one of two things:
(A – Good) Make the pitfall a diagnosed error, with zero false positives — every violation is a real bug. Two examples mentioned above are to automatically check a[b] to be in bounds and *p and p-> to be non-null.
(B – Ideal) Make the code actually do what the programmer intended, with zero false positives — i.e., fix it by just recompiling. An example, discussed at the most recent ISO C++ November 2023 meeting, is to default to an implicit return *this; when the programmer writes an assignment operator for their type C that returns a C& (note: the same type), but forgets to write a return statement. Today, that is undefined behavior. Yet it’s clear that the programmer meant return *this; — nothing else can be valid. If we make return *this; be the default, all the existing code that accidentally omits the return is not just “no longer UB,” but is guaranteed to do the right and intended thing.
An example of both (A) and (B) is to support chained comparisons, that makes the mathematically valid chains work correctly and rejects the mathematically invalid ones at compile time. Real-world code does write such chains by accident (see: [a][b][c][d][e][f][g][h][i][j][k]).
For (A): We can reject all mathematically invalid chains like a != b > c at compile time. This automatically diagnoses bugs in existing code that tries to do such nonsense chains, with perfect accuracy.
For (B): We can fix all existing code that writes would-be-correct chains like 0 <= index < max. Today those silently compile but are completely wrong, and we can make them mean the right thing. This automatically fixes those bugs, just by recompiling the existing code.
These examples are not exhaustive. We should review the list of UB in the standard for a more thorough list of cases we can automatically fix (ideally) or diagnose.
Summarizing: Better defaults for C++
C++ could enable turning safety rules on by default that would make code:
fully type-safe,
fully bounds-safe,
fully initialization-safe,
and for lifetime safety, which is the hardest of the four, and where I would expect the remaining vulnerabilities in these categories would mostly lie:
fully null-safe,
fully free of owning raw pointers,
with lifetime-safety static analysis that diagnoses most common pointer/iterator/view lifetime errors;
and, finally:
with less undefined behavior including by automatically fixing existing bugs just by recompiling code with safety enabled by default.
All of this is efficiently implementable and has been implemented. Most of the Lifetime rules have been implemented in Visual Studio and CLion, and I’m prototyping a proof-of-concept mode of C++ that includes all of the other above language safeties on-by-default in my cppfront compiler, as well as other safety improvements including an implementation of the current proposal for ISO C++ contracts. I haven’t yet used the prototype at scale. However, I can report that the first major change request I received from early users was to change the bounds checking and null checking from opt-in (off by default) to opt-out (on by default).
Note: Please don’t be distracted by that cppfront uses an experimental alternate syntax for C++. That’s because I’m additionally trying to see if we can reach a second orthogonal goal: to make the C++ language itself simpler, and eliminate the need to teach ~90% of the C++ guidance literature related to language complexity and quirks. This essay’s language safety improvements are orthogonal to that, however, and can be applied equally to today’s C++ syntax.
Solutions need to distinguish between (A) “solution for new-or-updatable code” and (B) “solution for existing code.”
(A) A “solution for new-or-updatable code” means that to help existing code we have to change/rewrite our code. This includes not only “(re)write in C#/Rust/Go/Python/…,” but also “annotate your code with SAL” or “change your code to use std::span.”
One of the costs of (A) is that anytime we write/change code to fix bugs, we also introduce new bugs; change is never free. We need to recognize that changing our code to use std::span often means non-trivially rewriting parts of it which can also create other bugs. Even annotating our code means writing annotations that can have bugs (this is a common experience in the annotation languages I’ve seen used at scale, such as SAL). All these are significant adoption barriers.
Actually switching to another language means losing a mature ecosystem. C++ is the well-trod path: It’s taught, people know it, the tools exist, interop works, and current regulations have an industry around C++ (such as for functional safety). It takes another decade at least for another language to become the well-trod path, whereas a better C++, and its benefits to the industry broadly, can be here much sooner.
(B) A “solution for existing code” emphasizes the adoptability benefits of not having to make manual code changes. It includes anything that makes existing code more secure with “just a recompile” (i.e., no binary/ABI/link issues; e.g., ASAN, compiler switches to enable stack checks, static analysis that produces only true positives, or a reliable automated code modernizer).
We will still need (B) no matter how successful new languages or new C++ types/annotations are. And (B) has the strong benefit that it is easier to adopt. Getting to a 98% reduction in CVEs will require both (A) and (B), but if we can deliver even a 30% reduction using just (B) that will be a major benefit for adoption and effective impact in large existing code bases that are hard to change.
Consider how the ideas earlier in this appendix map onto (A) and (B):
In C++, by default enforce …
(A) Solution for new/updated code (can require code changes — no link/binary changes)
(B) Solution for existing code (requires recompile only — no manual code changes, no link/binary changes)
Type safety
Ban all inherently unsafe casts and conversions
Make unsafe casts and conversions with a safe alternative do the safe thing
Bounds safety
Ban pointer arithmetic Ban unchecked iterator arithmetic
Check in-bounds for all allowed iterator arithmetic Check in-bounds for all subscript operations
Initialization safety
Require all variables to be initialized (either at declaration, or before first use)
—
Lifetime safety
Statically diagnose many common pointer/iterator lifetime error cases
Check not-null for all pointer dereferences
Less undefined behavior
Statically diagnose known UB/bug cases, to error on actual bugs in existing code with just a recompile and zero false positives: Ban mathematically invalid comparison chains (add additional cases from UB Annex review)
Automatically fix known UB/bug cases, to make current bugs in existing code be actually correct with just a recompile and zero false positives: Define mathematically valid comparison chains Default return *this; for C assignment operators that return C& (add additional cases from UB Annex review)
By prioritizing adoptability, we can get at least some of the safety benefits just by recompiling existing code, and make the total improvement easier to deploy even when code updates are required. I think that makes it a valuable strategy to pursue.
Finally, please see again the main post’s conclusion: Call(s) to action.