I presented you with a daunting unsorted list of ~300 eye-numbing paper titles, and still 289 of you responded with ~1,200 total votes (not everyone picked five things) many of which contained thoughtful “how I would use it” verbatims. Thank you for your time and interest!
In addition to summing your votes per-paper, I also spent several hours manually assigning categories to the individual proposals so that we could see votes per-feature area. For example, “pattern matching” had multiple papers, so I wanted to generate a subtotal also for votes for “all pattern-matching papers” as well as for each of the individual ones. You might assign categories differently than I did, but I think these are a good start to see basic groupings and patterns.
The top-voted primary topic categories correlate well with the results we saw in the 2019 global C++ developer survey open-ended write-in questions for ‘if you could change one thing about C++’ and ‘any other feedback.’ The top topic areas are:
Primary topic category
#votes
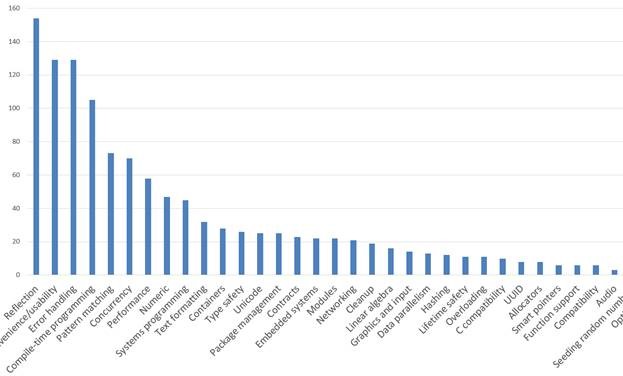
Reflection
154
Convenience/usability
129
Error handling
129
Compile-time programming
105
Pattern matching
73
Concurrency
70
Performance
58
Numeric
47
Systems programming
45
Here’s a partial graph:
The top-voted individual papers were:
Paper
#votes
P0707 reflection & metaclasses
89
P0709 error handling, static EH
85
P1371 pattern matching
71
P1240 reflection
40
P0323 error handling,
std::expected
24
P1767 package mgmt
23
P1485 coroutine keywords
23
P1750 std::process
22
P1717 compile-time programming
22
? no specific paper (a catchall when the response was useful and fit in a category, but didn’t include a specific paper number)
22
P1629 Unicode
20
P1031 low level file I/O
19
P1040 compile-time data embed
19
P0645 text formatting
16
P1729 text formatting
15
Finally, disclaimers:
Experimental: This was advertised as an experiment. The results may not be representative. However, as I mentioned already, the top-voted topic areas correlate well with the results from the 2019 global C++ developer survey open-ended write-in questions for ‘if you could change one thing about C++’ and ‘any other feedback.’
Bias: I posted the poll on my personal blog, which could bias results in favor of my proposals. In fact, the two top-voted individual proposals were my own papers on reflection and lightweight exceptions. But even if you remove those two, their topics are still in the top-voted categories of interest because there was strong voting in favor of “reflection” and “efficient exception/error handling” papers that were not written by me (e.g., the #4 and #5 papers were reflection and error handling papers that I didn’t write). Also, the post was Reddit’ed and it looks like most of the responses came via that. (Besides, happily/sadly, many of you who follow my blog freely disagree and argue with me so this isn’t just an echo chamber, and I also had a number of other papers that got fewer votes or none so you weren’t just upvoting my papers.)
Again, thank you very much to everyone who responded for your time and interest. I hope you find these results likewise interesting, and I’ve shared them with the committee as well.
I think this survey was a successful experiment. We’ll keep reading the data, especially the verbatims on how you would use the features you requested. But I think it’s fair that we can say already that, if nothing else, we now have some confirmation that the part of the community that responded supports the basic goals of P0592 so that paper is more than just the opinion of the author (who isn’t me)… that paper recommends that in the C++23 timeframe we focus our efforts on coroutines, executors, networking, reflection, and pattern matching. There’s a good correlation between that list and your “most-wanted papers’ topics” list above. That’s useful to learn, and we’ll look to learn more from your responses; thank you again.
At noon today, July 20 2019, the ISO C++ committee completed its summer meeting in Cologne, Germany, hosted with thanks by Think-Cell, SIGS Datacom, SimuNova, Silexica, Meeting C++, Josuttis Eckstein, Xara, Volker Dörr, Mike Spertus, and the Standard C++ Foundation.
As usual, we met for six days Monday through Saturday, and it was our biggest meeting yet with some 220 attendees. Here’s a visual, going back to when I first joined the committee:
Thank you to all of the hundreds of people who participate in ISO C++ in person and electronically. Below, I want to at least try to recognize by name many of the authors of the proposals we adopted, but nobody succeeds with a proposal on their own. C++ is a team effort – this wouldn’t be possible without all of your help. So, thank you, and apologies for not being able to acknowledge everyone by name.
Notes:
See also the Reddit trip report, which was collaboratively edited by several dozen committee members. It has lots of excellent detail.
Some of the links below are to papers that will not be published until the post-meeting mailing a few weeks from now, and so the links will start working at that time.
You can find a brief summary of ISO procedures here.
The main news: C++20 is feature complete, CD ships
Today we achieved feature freeze for C++20.
Per our official C++20 schedule, we are now feature-complete for C++20 and will send out the C++20 draft for its international comment ballot (Committee Draft, or CD) to run over the summer. After that, we will address national body comments and other fit-and-finish work for the next two meetings (November in Belfast, and February in Prague) and plan to ship the final text of the C++20 start at the end of the February meeting.
Here are the main proposals that were added into C++20 at
this meeting.
std::format for text
formatting (Victor Zverovich) adds format strings support to the C++
standard library, including for type-safe and positional parameters. If you’re familiar
with Boost.Format or POSIX format strings, or even just printf, you’ll know exactly
what this is about: It gives us the best of printf (convenience) and the best
of iostreams (type safety and extensibility of iostreams) – and it isn’t
limited to iostreams, it lets you format any string. I’ve been waiting for this
for a long time, so that I will never have to use header iomanip again.
Applying <=> (spaceship) comparisons throughout the standard library (Barry Revzin) uses the new <=> feature and applies it throughout namespace std to basically everything. It’s great to see a new language feature we added in C++20 already used widely in the standard library itself in the same release. And it’s not alone: C++20 also added concepts and also the concepts-based ranges library in the same release.
And also, in the “moar constexpr!” and “constexpr all the
things!” departments:
We added constexpr INVOKE (Tomasz Kamiński and Barry Revzin), constexpr std::vector (Louis Dionne), and constexpr std::string (Louis Dionne). If all this constexpr surprises you, and in particular if constexpr std::vector and std::string make you do a double-take: Remember that we already added constexpr new (think about that and grok what it means) and made much of the standard library constexpr and added consteval to the language… and all told this means that a whole lot of ordinary C++ code can run at compile time, now including even the standard dynamic vector and string containers. This is something that would have been difficult to imagine just a few years ago, but it shows ever more that we’re on a path where we can run plain C++ code at compile time instead of trying to express those computations as template metaprograms. As many people have said: “More metaprogramming, less template metaprogramming!” We didn’t have to invent a new ‘compile-time C++’ dialect; this is just C++, running at compile time. This trend is good.
There are dozens of additional proposals we adopted besides
these, all of them good work, and I want to repeat our great thanks to all the
proposal authors and also the even larger number of people who helped them with
their proposals without whom this could not have happened. Thank you for your
time and effort on behalf of millions of C++ developers worldwide who will
benefit from your hard and careful work!
Contracts moved from draft C++20 to a new Study Group
At this meeting, it became clear that we were not quite done designing the contracts feature in time for C++20. Back when we adopted the feature one year ago we thought it was baked and ready for the standard, but since then we have discovered lingering design disagreements and concerns that we could not resolve sufficiently to get consensus (general agreement without sustained objections). All the main contracts proposers unanimously agreed that the right thing to do is to defer its release.
But contracts is an important feature, and work on contracts
is not stopping, but actually increasing: The contracts proposers made good
progress at this meeting toward starting to identify and iron out the
differences, and we formed a new Study Group for Contracts, SG21, with John
Spicer as the chair that will continue work with even greater participation. I’m
hopeful that over the coming meetings we’ll see some solid further progress in this
important area.
The shape of C++20
Now that we know the final feature set of C++20, we can see this
is C++’s largest release since C++11. “Major” features include:
modules
coroutines
concepts including in the standard library via ranges
<=> spaceship including in the standard library
broad use of normal C++ for direct compile-time programming, without resorting to template metaprogramming (see last trip reports)
ranges
calendars and time zones
text formatting
span
… and lots more …
Combined with what came in C++14 and C++17, the C++14/17/20
nine-year cycle is arguably our biggest nine-year cycle alongside the previous
two (C++98 and C++11). We understand that’s exciting, but we also understand
that’s a lot for the community to absorb, and so I’m also pleased that along
the way we’ve done things like create the Direction Group and, most recently,
SG20 on Education, to help guide and absorb continued C++ evolution in our
vibrant living language.
It was not lost on the room that today was not just the day we completed the feature set of C++20, but it was also the 50th anniversary of the Apollo 11 lunar landing. A number of people mentioned it throughout the week and especially today, some citing examples from that voyage and drawing parallels that ranged from insightful to side-splittingly funny. Here is one that I contributed after we had the vote to adopt the draft, with profuse apologies to Neil Armstrong that I couldn’t come up with something even better (sorry!):
There’s no doubt about it, C++20 is a big release with many
new and important features. It’s almost done as we now enter the review and fit-and-finish
phases… as we complete the work to ship the new standard over the coming two
meetings, and as it then gradually becomes available for you to use in C++
implementations, we hope you will find it a useful and compelling release.
Oh, and here’s a public service announcement… even without contracts we can still make “co” jokes:
As someone pointed out to me after the session ended: This was, after all, the co_logne meeting.
Other progress and decisions
Because for the past year we’ve been focused on finishing C++20,
I’ve been holding back from publishing updates to my own P0707 and P0709
proposals, generation+metaclasses and lightweight exception handling. At this
meeting, I brought updates to both of those proposals again. In Study Group 7
(Compile-Time Programming) I showed an updated of P0707 and Andrew Sutton and
Wyatt Childers presented updates on the Clang-based implementation progress. In
the Evolution subgroup, I presented P0709 for the first time and received broad
encouragement for most of the proposal along with a list of questions to which
I’ll come back with answers in Belfast.
Thank you again to the approximately 220 experts who attended this meeting, and the many more who participate in standardization through their national bodies! If today our C++20 Eagle has wings, our next step is to land it, then bring it home… and so in our next two regular WG21 meetings, in November (Belfast, Northern Ireland, UK) and February (Prague, Czech Republic), we plan to respond to the C++20 international review ballot comments and make other bugfixes before sending final C++20 out for its approval ballot about seven months from now.
Have a good summer… and see many of you (and a large part of
the committee) at CppCon in September!
WG21 has a strict schedule (see P1000) by which we ship the standard every three years. We don’t delay it.
Around this time of each cycle, we regularly get questions about “but why so strict?”, especially because we have many new committee members who aren’t as familiar with our history and the reasons why we do things this way now. And so, on the pre-Cologne admin telecon last Friday, several of the chairs encouraged me to write down the reasons why we do it this way, and some of the history behind the decision to adopt this schedule.
I’ve now done that by adding a FAQ section to the next draft of P1000, and I’ve sent a copy of it to the committee members now en route to Cologne. That FAQ material will appear in the next public revision of P1000 which will be in the post-meeting mailing a few weeks from now.
In the meantime, because the draft FAQ might be of general public interest too, here is a copy of that material. I hope you find it largely useful, occasionally illuminating, and maybe even a bit entertaining.
Now off to the airport… see (many of) you in Cologne. We are expecting about 220 people… by far our largest meeting ever. More about that in the post-meeting trip report after the meeting is over…
FAQs
(As of pre-Cologne, July 2019) There are bugs in the standard, so should we
delay C++20?
Of course, and no.
We are on our planned course and speed: Fixing bugs is the
purpose of this final year, and it’s why this schedule set the feature freeze
deadline for C++“20” in early “19” (Kona), to leave a year to fix bugs
including to get a round of international comments this summer. We have until
early 2020 (three meetings: Cologne, Belfast, and Prague) to apply that review
feedback and any other issue resolutions and bug fixes.
If we had just another meeting or two, we could add <feature> which
is almost ready, so should we delay C++20?
Of course, and no.
Just wait a couple more meetings (post-Prague) and C++23
will be open for business and <feature> can be the first thing voted into
the C++23 working draft. For example, that’s what we did with concepts; it was
not quite ready to be rushed from its TS straight into C++17, so the core
feature was voted into draft C++20 at the first meeting of C++20 (Toronto),
leaving plenty of time to refine and adopt the remaining controversial part of
the TS that needed a little more bake time (the non-“template” syntax) which
was adopted the following year (San Diego). Now we have the whole thing.
This feels overly strict. Why do we ship releases of the IS at fixed time
intervals (3 years)?
Because it’s one of only two basic project management
options to release the C++ IS, and experience has demonstrated that it’s better
than the other option.
What are the two project management options to release the C++ IS?
I’m glad you asked.
There are two basic release target choices: Pick the features, or pick the release time, and whichever you pick means relinquishing control over determining the other. It is not possible to control both at once. They can be summarized as follows:
Elaborating:
(1) “What”: Pick the features, and ship when they’re
ready; you don’t get to pick the release time. If you discover that a
feature in the draft standard needs more bake time, you delay the world until
it’s ready. You work on big long-pole features that require multiple years of
development by making a release big enough to cover the necessary development
time, then try to stop working on new features entirely while stabilizing the
release (a big join point).
This was the model for C++98 (originally expected to ship
around 1994; Bjarne originally said if it didn’t ship by about then it would be
a failure) and C++11 (called 0x because x was expected to be around 7). This
model “left the patient open” for indeterminate periods and led to delayed
integration testing and release. It led to great uncertainty in the marketplace
wondering when the committee would ship the next standard, or even if it would
ever ship (yes, among the community, the implementers, and even within the
committee, some had serious doubts in both 1996 and 2009 whether we would ever
ship the respective release). During this time, most compilers were routinely several
years behind implementing the standard, because who knew how many more
incompatible changes the committee would make while tinkering with the release,
or when it would even ship? This led to wide variation and fragmentation in the
C++ support of compilers available to the community.
Why did we do that, were we stupid? Not exactly, just inexperienced
and… let’s say “optimistic,” for (1) is the road paved with the best of
intentions. In 1994/5/6, and again in 2007/8/9, we really believed that if we
just slipped another meeting or three we’d be done, and each time we ended up
slipping up to four years. We learned the hard way that there’s really no such
thing as slipping by one year, or even two.
Fortunately, this has changed, with option (2)…
(2) “When”: Pick the release time, and ship what features
are ready; you don’t get to pick the feature set. If you discover that a
feature in the draft standard needs more bake time, you yank it and ship what’s
ready. You can still work on big long-pole features that require multiple
releases’ worth of development time, by simply doing that work off to the side
in “branches,” and merging them to the trunk/master IS when they’re ready, and
you are constantly working on features because every feature’s development is
nicely decoupled from an actual ship vehicle until it’s ready (no big join
point).
This has been the model since 2012, and we don’t want to go
back. It “closes the patient” regularly and leads to sustaining higher quality
by forcing regular integration and not merging work into the IS draft until it
has reached a decent level of stability, usually in a feature branch. It also
creates a predictable ship cycle for the industry to rely on and plan for.
During this time, compilers have been shipping conforming implementations
sooner and sooner after each standard (which had never happened before), and in
2020 we expect multiple fully conforming implementations the same year the
standard is published (which has never happened before). This is nothing but
goodness for the whole market – implementers, users, educators, everyone.
Also, note that since we went to (2), we’ve also been
shipping more work (as measured by big/medium/small feature counts) at higher
quality (as measured by a sharp reduction in defect reports and comments on
review drafts of each standard), while shipping whatever is ready (and if
anything isn’t, deferring just that).
How serious are we about (2)? What if a major feature by a prominent
committee member was “almost ready”… we’d be tempted to wait then, wouldn’t we?
Very serious, and no.
We have historical data: In Jacksonville 2016, at the
feature cutoff for C++17, Bjarne Stroustrup made a plea in plenary for including
concepts in C++17. When it failed to get consensus, Stroustrup was directly asked
if he would like to delay C++17 for a year to get concepts in. Stroustrup said No
without any hesitation or hedging, and added that C++17 without concepts was
more important than a C++18 or possibly C++19 with concepts, even though Stroustrup
had worked on concepts for about 15 years. The real choice then was between:
(2) shipping C++17 without concepts and then C++20 with concepts (which we
did), or (1) renaming C++17 to C++20 which is isomorphic to (2) except for
skipping C++17 and not shipping what was already ready for C++17.
What about something between (1) and (2), say do basically (2) but with “a
little” schedule flexibility to take “a little” extra time when we feel we need
to stabilize a feature?
No, because that would be (1).
The ‘mythical small slip’ was explained by Fred Brooks in The
Mythical Man-Month, with the conclusion: ”Take
no small slips.”
For a moment, imagine we did slip C++20. The reality is that
we would be switching from (2) back to (1), no matter how much we might try to
deny it, and without any actual benefit. If we decided to delay C++20 for more
fit-and-finish, we will delay the standard by at least two years. There is no
such thing as a one-meeting or three-meeting slip, because during this time
other people will continue to (rightly) say “well my feature only needs one
more meeting too, since we’re slipping a meeting let’s add that too.” And once
we slip at least two years, we’re saying that C++20 becomes C++22 or more
likely C++23… but we’re already going to ship C++23! — So we’d still be
shipping C++23 on either plan, and the only difference is that we’re not
shipping C++20 in the meantime with the large amount of fully-baked work that’s
ready to go, and making the world wait three more years for it. Gratuitously,
because the delay will not benefit those baked features, which is most or all
of them.
So the suggestion amounts to “let’s make C++20 be C++22 or
C++23,” and the simple answer is “yes, we’re going to have C++23 too, but in
addition to C++20 and not instead of it.” To delay C++20 actually means to skip
C++20, instead of releasing the great good work that is stable and ready, and
there’s no benefit to doing that.
But feature X is broken / needs more bake time than we have bugfix time
left in C++20!
No problem! We can just pull it.
In that case, someone needs to write the paper aimed at EWG
or LEWG (as appropriate) that shows the problem and/or the future doors we’re
closing, and proposes removing it from the IS working draft. Those groups will
consider it, and if they decide the feature is broken (and plenary agrees),
that’s fine, the feature will be delayed to C++next. We have actually done this
before, with C++0x concepts.
But under plan (1), we would be delaying, not only that
feature, but the entire feature set of C++20 to C++23! That would be…
excessive.
Does (2) mean “major/minor” releases?
No. We said that at first, before we understood that (2) really
simply means you don’t get to pick the feature set, not even at a “major/minor”
granularity.
Model (2) simply means “ship what’s ready.” That leads to
releases that are:
similarly sized (aka regular medium-sized) for “smaller”
features because those tend to take shorter lead times (say, < 3 years each)
and so generally we see similar numbers completed per release; and
variable sized (aka lumpy) for “bigger” features
that take longer lead times (say, > 3 years each) and each IS release gets
whichever of those mature to the point of becoming ready to merge during that
IS’s time window, so sometimes there will be more than others.
So C++14 and C++17 were relatively small, because a lot of
the standardization work during that time was taking place in long-pole features
that lived in proposal papers (e.g., contracts) and TS “feature branches”
(e.g., concepts).
C++20 is a big release …
Yes. C++20 has a lot of major features. Three of the biggest
all start with the letters “co” (concepts, contracts, coroutines) so perhaps we
could call it co_cpp20. Or co_dependent. Wait,
we’re digressing.
… and so aren’t we cramming a lot into a three-year cycle for C++20?
No, see “lumpy” above.
C++20 is big, not because we did more work in those three
years, but because many long-pole items (including at least two that have been
worked on in their current form since 2012, off to the side as P-proposals and
TS “branches”) happened to mature and get consensus to merge into the IS draft
in the same release cycle.
It has pretty much always been true that major features take
many years. The main difference between plan (1) for C++98 and C++11 and plan
(2) now is: In C++98 and C++11 we held the standard until they were all ready,
now we still ship those big ones when they’re ready but we also ship other
things that are ready in the meantime instead of going totally dark.
C++20 is the same 3-year cycle as C++14 and C++17; it’s not
that we did more in these 3 years than in the previous two 3-year cycles, it’s
just that more long-pole major features became ready to merge. And if any
really are unready, fine, we can just pull them again and let them bake more
for C++23. If there is, we need that to be explained in a paper that proposes
pulling it, and why, for it to be actionable.
In fact, I think the right way to think about it is that
C++14+17+20 taken as a whole is our third 9-year cycle (2011-2020), after C++98
(1989-1998) and C++11 (2002-2011), but because we were on plan (2) we also
shipped the parts that were ready at the 3- and 6-year points.
Isn’t it better to catch bugs while the product is in development, vs. after
it has been released to customers?
Of course.
But if we’re talking about that as a reason to delay the C++
standard, the question implies two false premises: (a) it assumes the features
haven’t been released and used before the standard ships (many already have
production usage experience); and (b) it assumes all the features can be used
together before the standard ships (they can’t).
Elaborating:
Re (a): Most major C++20 features have been implemented in
essentially their current draft standard form in at least one shipping
compiler, and in most cases actually used in production code (i.e., has already
been released to customers who are very happy with it). For example, coroutines
(adopted only five months ago as of this writing) has been used in production
in MSVC for two years and in Clang for at least a year with very happy
customers at scale (e.g., Azure, Facebook).
Re (b): The reality is that we aren’t going to find many feature interaction problems until users are using them in production, which generally means until after the standard ships, because implementers will generally wait until the standard ships to implement most things. That’s why when we show any uncertainty about when we ship, what generally happens is that implementations wait – oh, they’ll implement a few things, but they will hit Pause on implementing the whole thing until they know we’re ready to set it in stone. Ask <favorite compiler> team what happened when they implemented <major feature before it was in a published standard>. In a number of cases, they had to implement it more than once, and break customers more than once. So it’s reasonable for implementers to wait for the committee to ship.
Finally, don’t forget the feature interaction problem. In
addition to shipping when we are ready, we need time after we ship to find and
fix problems with interactions among features and add support for such
interactions that we on typically cannot know before widespread use of new
features. No matter how long we delay the standard, there will be interactions
we can’t discover until much later. The key is to manage that risk with design
flexibility to adjust the features in a compatible way, not to wait until all
risk is done.
The standard is never perfect… don’t we ship mistakes?
Yes.
If we see a feature that’s not ready, yes we should pull it.
If we see a feature that could be better, but we know that
the change can be done in a backward-compatible way, that’s not a reason to not
ship it now; it can be done as an extension in C++next.
We do intentionally ship features we plan to further
improve, as long as we have good confidence we can do so in a
backward-compatible way.
But shouldn’t we aim to minimize shipping mistakes?
Yes. We do aim for that.
However, we don’t aim to eliminate all risk. There is also a
risk and (opportunity) cost to not shipping something we think is ready. So
far, we’ve been right most of the time.
Are we sure that our quality now is better than when were on plan (1)?
Yes.
By objective metrics, notably national body comment volume and defect reports, C++14 and C++17 have been our most stable releases ever, each about 3-4 times better on those metrics than C++98 or C++11. And the reason is because we ship regularly, and put big items into TS branches first (including full wording on how they integrate with the trunk standard) and merge them later when we know they’re more baked.
In fact, since 2012 the core standard has always been
maintained in a near-ship-ready state (so that even our working drafts are at
least as high quality as the shipped C++98 and C++11 standards). That never
happened before 2012, where we would often keep the patient open with long
issues lists and organs lying around nearby that we meant to put back soon; now
we know we can meet the schedule at high quality because we always stay close
to a ship-ready state. If we wanted to, we could ship the CD right now without
the Cologne meeting and still be way higher quality than C++98’s or C++11’s CDs
(or, frankly, their published standards) ever were. Given that C++98 and C++11
were successful, recognizing that we’re now at strictly higher quality than
that all the time means we’re in a pretty good place.
C++98 and C++11 each took about 9 years and were pretty good products …
Yes: 1989-1998, and 2002-2011.
… and C++14 and C++17 were minor releases, and C++20 is major?
Again, I think the right comparable is C++14+17+20 taken as
a whole: That is our third 9-year cycle, but because we were on plan (2) we also
shipped the parts that were ready at the 3- and 6-year points.
Does (2) allow making feature-based targets like P0592 for C++next?
Sure! As long as it doesn’t contain words like “must include
these features,” because that would be (1).
Aiming for a specific set of features, and giving those ones
priority over others, is fine – then it’s a prioritization question. We’ll
still take only what’s ready, but we can definitely be more intentional about
prioritizing what to work on first so it has the best chance of being ready as
soon as possible.
The ISO C++ committee now regularly receives many more proposals than we can/should accept. For the meeting that begins this coming Monday, we have about 300 active technical papers, most targeting post-C++20. I now regularly get asked, including again a few hours ago, “how do we know which of these customers actually want and will use? what is our data that we’ve prioritized them correctly?”
So a colleague has challenged me: Can the ISO C++ committee get useful information by crowdsourcing public feedback on ISO C++ proposals? I don’t know, so let me try by asking one targeted question…
I don’t expect you to know all of the proposals (and I know it’s a big list!), but I suspect many of you know about some of them that matter to you. I will share your feedback with the ISO C++ committee and post the results publicly. Thanks again for all of you who’ve already provided feedback in our spring C++ developer survey, that feedback is being used by the committee and the experiment here is try for finer-grained feedback at the proposal level. If this works perhaps we can explore things like allowing community comment/upvote on these issues.
Thank you in advance for your time, it’s appreciated and helpful.
Herb
Note: PLEASE use the survey (not the comments section on this post) to respond to this question, because the survey form makes it easier to track and use the data.
Please do use the comments section below for other discussion, including suggestions about other ways the committee might usefully engage the community.
Note that when he says “growing a language” he doesn’t mean literally the language itself — it’s not a talk about language evolution. Rather, he’s talking about enabling users to write rich and powerful abstractions in that language without having to go beg their language designer and compiler vendor to build them into the compiler every time.
Steele’s argument in the back half of the talk is on point, on the importance of imbuing a programming language with a few well-chosen “patterns” that allow, and guide, specific kinds of extensibility. His argument is a great description of why I’m pursuing metaclasses for C++, because we should have a convenient way for programmers to write their own Words of Power like “value_type” or “interface” as libraries instead of forcing them to go bother their local compiler writer (or local standards committee) for a language extension each time for that sort of thing. And his “as a pattern” description is a great summary of why I’m proposing them as “just” a sugar to apply a compile-time function in a very specific place and in a very constrained way, and not going anywhere near making a mutable language which would be crazy not worth pursuing.
This week I was happy to join Rob Irving and Jason Turner on their great CppCast podcast. I chose “Simplifying C++” as the theme, because all of the active work I’ve chosen to do on C++ these days is on the common theme of simplifying how we teach, learn, and use C++… the “C++ UX” you might say.
And here’s a table that summarizes my active projects that we mentioned in the podcast, and what specific parts of C++ that I hope each might help simplify.
You’ll notice that three common “simplification” themes get their own summary columns: Can this project reduce what we have to teach/know to use C++, so that C++ can be easier to learn and use? Can it reduce or even eliminate classes of errors, so that we can program with greater confidence? And can it reduce the need for future language features, to help reduce future complexity as C++ continues to grow and evolve?
Incidentally, this pattern is why I chose the title “Thoughts on a more powerful and simpler C++ (5 of N)” for my CppCon talk last year — it was the 5th CppCon plenary session I’d given on this theme, so I thought I might as well make the theme explicit.
At CppCon 2018, I gave an update of my Lifetime analysis work that makes common cases of pointer/iterator/range/etc. dangling detectable at compile time (the spec is here in the C++ Core Guidelines GitHub repo). During that talk, we mentioned and demo’d two implementations: as a Visual C++ extension by Kyle Reed and Neil MacIntosh, and in a fork of Clang by Matthias Gehre and Gábor Horváth who both also joined me on-stage.
Last month at EuroLLVM, Matthias and Gábor gave a 30-minute progress report talk about their work to upstream the Lifetime rules implementation into Clang, “Implementing the C++ Core Guidelines’ Lifetime Safety Profile in Clang.” They give a summary of the approach and how it maps to Clang internals, show initial results from testing against Clang’s and LLVM’s own sources, and end with a nice roadmap for the next steps of incrementally upstreaming the work to Clang trunk.
If you care about making C++ safer, I recommend taking a look… it’s a great summary and update. Thanks, Matthias and Gábor and Kyle and Neil for their collaboration on this project!
A few minutes ago, the ISO C++ committee completed its winter meeting in Kona, HI, USA, hosted with thanks by Plum Hall, NVIDIA, and the Standard C++ Foundation. As usual, we met for six days Monday through Saturday, including most evenings. This and the previous meeting were the biggest ISO C++ meetings in our 29-year history, and this time we had a new record of 13 voting national bodies represented in person: Bulgaria, Canada, Czech Republic, Finland, France, Germany, Netherlands, Poland, Russia, Spain, Switzerland, United Kingdom, and United States. For more details about our size increase, including how we adapted organizationally to handle the load, see my San Diego “pre-trip” report and my San Diego trip report.
Thank you to all of the hundreds of people who participate in ISO C++ in person and electronically. Below, I want to at least try to recognize by name many of the authors of the proposals we adopted, but nobody succeeds with a proposal on their own. C++ is a team effort – this wouldn’t be possible without all of your help. So, thank you, and apologies for not being able to acknowledge everyone by name.
Notes:
Some of the links below are to papers that will not be published until the post-meeting mailing a few weeks from now, and so the links will start working at that time.
You can find a brief summary of ISO procedures here.
C++20 feature freeze
Per our official C++20 schedule, this was the last meeting to approve features for C++20, so we gave priority to proposals that might make C++20 or otherwise could make solid progress, and we deferred other proposals to be considered at a future meeting — not at all as a comment on the proposals, but just for lack of time at this meeting. (I’ve been holding back from publishing updates to my own P0707 and P0709 proposals, generation+metaclasses and lightweight exception handling, for this very reason.)
So we now know most of the final feature set of C++20! At our next meeting in July, we expect to formally adopt a few additional features that were design-approved at this meeting but didn’t complete full wording specification review this week, and then at the end of the July meeting we will launch the primary international comment ballot (aka CD ballot) for C++20.
Two more major features adopted for C++20: Modules and coroutines
Again, I want to acknowledge the primary proposal authors by name, who did a lot of the heavy lifting. But none of this would be possible without the hard work of scores of people at this meeting and over the past few years including in alternative proposals.
Modules (Gabriel Dos Reis, Richard Smith) was adopted for C++20. Modules are a new alternative to header files that deliver a number of key improvements, notably isolating the effects of macros and enabling scalable builds. As I’ve said in talks (another example), I personally find this feature very significant for several reasons, but the most fundamental is that this is the first time in about 35 years that C++ has added a new feature where users can define a named encapsulation boundary. Until now, we have had three such language features that let programmers create their own Words of Power by (a) giving a user-defined name to (b) something whose implementation is hidden. They are: the variable (which encapsulates the current value), the function (which encapsulates code and behavior), and the class (which encapsulates both to deliver a bunch of state and functions together). Even other major features such as templates are ways to adorn or parameterize those three fundamental features. To these three we now add a fourth: the module (which encapsulates all three to deliver a bunch of them together). That’s a fundamental reason underlying why modules enable further improvements that can now follow on in future C++ evolution.
<=> != == (Barry Revzin) adds better language support for composability when writing <=> for types that can write a more efficient == than using the <=> operator alone. For example, vector<T> can short-circuit == comparison by first checking whether the two vectors have the same size; if they don’t, we know in constant time that they cannot be equal without comparing any of the elements. The previous guidance for such types was that in addition to <=> they should also overload == and !=, and that any types that compose such types have to know to do the same so as not to lose the optimization. With this change, we can more simply teach that for such types in addition to <=> they should also overload ==, full stop; there is no need to also overload !=, and no need for other types that use such a type to be especially careful so avoid losing the optimization .
A slew of broad papers restating the standard library in terms of our new C++20 language features of concepts and contracts that were already adopted at recent meetings. See P0788 and P1369 for a great overview of what this involves. This is part of the standard library’s intentional evolution toward replacing exceptions with contracts for preconditions (such as domain and range errors) in future C++.
Lots of smaller features and individual issues resolutions.
Other features targeting C++20 for the July meeting
Several other features were design-approved for C++20 this week but did not yet have their specification wording reviewed to merge into the working draft at this meeting, and they are hoped to be formally adopted at our July meeting in Cologne. These include things like text formatting, flat_map, more ranges and algorithms such as move-only views, an automatically joining thread with stop token support, and more. I’ll cover which of these are actually adopted in my July trip report, when we know what landed at that meeting.
The shape of C++20 (modulo any additional features in July)
Now that we are close to knowing the final feature set of C++20, we can see will be C++’s largest release since C++11. “Major” features include at least the following:
modules
coroutines
concepts
contracts
<=> spaceship
“lots more constexpr”: broad use of normal C++ for direct compile-time programming, without resorting to template metaprogramming (see last trip report)
ranges
calendars and time zones
span
and lots more
Combined with what came in C++14 and C++17, the C++14/17/20 nine-year cycle is arguably our biggest nine-year cycle yet alongside the previous two (C++98 and C++11) in terms of new features added. We understand that’s exciting, but we also understand that’s a lot for the community to absorb, and so I’m also pleased that along the way we’ve done things like create the Direction Group and, most recently, SG20 on Education, to help guide and absorb continued C++ evolution in our vibrant living language.
Other progress and decisions
Executors and Networking: Both of these continue to progress together, as Networking depends on Executors. We had hoped that part of Executors might be ready for C++20 but they didn’t make the cut, and both of these are now on track for soon post-C++20 (i.e., early in the C++23 cycle).
Reflection TS v1 (David Sankel, Axel Naumann) completed. The Reflection TS international comments have now been processed and the TS is approved for publication. As I mentioned in other trip reports, note again that the TS’s current template metaprogramming-based syntax is just a placeholder; the feedback being requested is on the core “guts” of the design, and the committee already knows it intends to replace the surface syntax with a simpler programming model that uses ordinary compile-time code and not <>-style metaprogramming.
Thank you again to the approximately 180 experts who attended this meeting, and the many more who participate in standardization through their national bodies! Have a good spring… our next regular WG21 meeting in July (Cologne, Germany) where we plan to send out C++20 for its major international review ballot, then spend two more meetings responding to those review comments and make other bugfixes before sending final C++20 out for its approval ballot one year from now.
On Saturday November 10, the ISO C++ committee completed its fall meeting in San Diego, California, USA, hosted with thanks by Qualcomm. This was the biggest ISO C++ meeting in our 29-year history, with some 180 people at the meeting, representing 12 nations. For more details about our size increase, including how we adapted organizationally to handle the load, see my “pre-trip report” posted before the meeting began.
Because this is one of the last meetings for adding features to C++20, we gave priority to proposals that might make C++20, and we adopted a number of them for C++20. Thank you to all of the hundreds of people who participate in ISO C++, those who came to the meeting and still more who participated electronically, and who all helped with the design refinement and specification wording and organization. I want to at least try to recognize by name many of the authors of the proposals we adopted, but nobody succeeds with a proposal on their own. C++ is a team effort – this wouldn’t be possible without all of your help. So, thank you, and apologies for not being able to acknowledge everyone by name.
Notes:
Some of the links below are to papers that will not be published until the post-meeting mailing at the end of this month, and so the links will become public at that time.
You can find a brief summary of ISO procedures here.
Prelude: Focus
The committee is actively working to keep coherence and direction in the face of a tsunami of proposals and a huge number of enthusiastic people. Perhaps the most impactful record-setting number was the size of the pre-meeting mailing: 274 papers. For comparison, even excluding the biggest paper which was the updated C++ standard working draft which appears in every mailing, the pre-meeting mailing was enormous:
By word count, it exceeded Shakespeare’s complete published works.
By paper count, it exceeded the previous pre-meeting papers record by about 65%, and started to approach the total number of technical papers to produce the first C++ standard (total of pre-meeting mailings from 1990-1997).
We appreciate all the input, including that many of the papers are about bug fixes (always welcome) and rounding out existing features. However, a large number were proposals for new “good” features. And the trouble is that we can’t say yes to every feature that is “good” that benefits some users; we have to decide on a focused set, of at least coordinated features and ideally of general composable features, that fulfills the aim and mission of C++ and keeps the language adoptable and usable.
As I reminded in my pre-trip report, focus means saying no more often, and so we’ve taken several steps in recent meetings and at this meeting:
About a year ago, we created the Direction Group (Bjarne Stroustrup, Daveed Vandevoorde, Michael Wong, Howard Hinnant, Roger Orr, and the recently retired Beman Dawes) which has created and maintains an advisory document Direction for ISO C++ (P0939).
In 2018, Pearson Education made free electronic copies of The Design and Evolution of C++ (Bjarne Stroustrup) available to all committee members. Not only does this help ensure that the newer people have access to this expected-to-be-read foundational work, which continues to be very current, but also having it in machine-readable and -searchable form makes it much easier to reference and quote from in our own papers.
At this meeting, we let EWG and LEWG continue to focus on near-term papers, and created SG17 (EWG Incubator, JF Bastien) and SG18 LEWG Incubator (Bryce Adelstein Lelbach) to help review and improve the papers that EWG and LEWG could not handle, to improve them and to prune them before they reach the main subgroup. Thank you to JF and Bryce for being willing to chair these new groups!
Two major features adopted for C++20: Ranges, and Concepts convenience notation
Ranges (Eric Niebler, Casey Carter, Christopher Di Bella) was adopted for C++20. This was a tremendous amount of work by Casey Carter in particular (witness the recurring 3:00am editing update emails during the week). As Eric Niebler put it: “If you liked the Ranges TS, you’ll love C++20.”
Concepts “convenience” notation for constrained templates (Ville Voutilainen, Thomas Köppe, Andrew Sutton, Herb Sutter, Gabriel Dos Reis, Bjarne Stroustrup, Jason Merrill, Hubert Tong, Eric Niebler, Casey Carter, Tom Honermann, Erich Keane, Walter E. Brown, Michael Spertus) passed unanimously on Saturday. I highlighted this paper as a “we may have a winner here” in my last trip report, and indeed it sailed through and was adopted for C++20. Recall that we already added the concepts core feature to C++20 back in 2017, but without the convenience notation to write templates without the “template” or “requires” keywords; at this meeting we finally converged on a convenience syntax to write constrained templates that both addressed all the major problems people had identified in the Concepts TS convenience notation design, and was also acceptable to the primary concepts designers (hence the long list of coauthors). For the first time, besides the special case of generic lambdas, C++ will now let you write lots of generic functions without “template” or angle brackets, and that are concept-constrained and therefore much easier to use correctly than function templates have ever been before.
More constexpr adopted for C++20: Ongoing concerted push toward general compile-time programming
In the first part of my CppCon 2017 talk, I emphasized that C++ is serious about first-class compile-time programming. That is a general theme to current C++ evolution, and is particularly important for being able to make effective use of compile-time reflection, and for building on that further in the future for compile-time code generation such as my metaclasses proposal relies upon.
First-class compile-time programming in C++ has been building since we allowed simple one-liner constexpr functions in C++11, to constexpr functions with loops in C++14, to constexpr lambdas and “if constexpr” in C++17. This week, we have added still more as a coordinated set of additions to C++20:
constexpr try and catch (Louis Dionne) lets you write try/catch in constexpr code. However, note that it doesn’t actually let you throw exceptions at compile time.
std::is_constant_evaluated (also by Richard Smith, Andrew Sutton, Daveed Vandevoorde) lets you write conditional code that lets you write part of a function using code that is guaranteed to be executed at compile-time. Another way to think of it is that it’s similar in spirit to “if constexpr” except that it lets you combine “if constexpr” with an “else normal-if.”
constexpr std::pointer_traits (Louis Dionne) is an essential ingredient for enabling compile-time reflection and especially compile-time std::vector. (Compile-time std::vector will also need compile-time new, still under development.)
We’re on track to making most “normal” C++ code available to run at compile time — and although C++20 won’t get quite all the way there, C++20 is a landmark release and a turning point where start to permanently leave behind the angle brackets and workarounds we’ve been using since the 1990s, with the near-complete birth of fully “natural” compile-time C++ code. Recall that we have already been adding support for user-defined types as template parameter types; soon (either before or after C++20’s feature freeze) we may be able to use strings as template arguments, and use containers like std::vector in compile-time code. Of course, there likely will be some limits; for example, supporting compile-time std::thread is possible, but less likely to be worth the effort.
Looking ahead to C++23 for a moment, where we expect still more of that plus (we hope) full static reflection in the standard, this marks a difficult-to-overstate landmark shift in C++ programming — not a course change, but really taking all the things that programmers have already been trying to do indirectly and giving it first-class natural support. The long-term results are likely to exceed our expectations in ways that we can’t fully anticipate yet. So fasten your seat belts, and stay tuned. C++ programming is likely to evolve more, and in better ways, in the upcoming 5 years than it already has in the past 20.
Other changes approved for C++20
A number of other smaller changes were adopted as well.
Signed integers are two’s complement (JF Bastien) is the result of a courtroom drama in both WG21 (C++) and WG14 (C). After intense prosecutorial cross-examination, the witness finally admitted in both courts that, yes, all known modern computers are two’s complement machines, and, no, we don’t really care about using C++ (or C) on the ones that aren’t. The C standard is likely to adopt the same change.
Missing feature test macros (John Spicer) adds support for missing macros that let code test for the presence of three features: destroying delete, three-way comparison (spaceship), and conditional explicit.
Several cleanup updates to std::optional, std::variant, std::function.
Lots of smaller features and individual issues resolutions.
Other progress and decisions
Modules (Richard Smith; and Gabriel Dos Reis) for the first time had a unified design approved targeting C++20. Wording specification work will continue over the holidays, and we expect to consider modules for C++20 at our next meeting in February.
Executors: Thanks to progress between meetings and special meeting in September, we now are hopeful that an initial Executors design can make it for C++20. The feature was not merged at this meeting, but the design was approved for C++20 and we expect to consider adding the wording specification to C++20 at our next meeting.
Coroutines: We continued to make progress on coroutines. At this meeting, EWG again recommended merging the Coroutines TS (Gor Nishanov) into C++20, and this time EWG additionally explicitly included plans to incorporate features from the competing Core Coroutines proposal (Geoff Romer, James Dennett, Chandler Carruth). As in Rapperswil, the vote to merge the Coroutines TS into C++20 fell just short numerically and was not adopted for C++20 at this meeting. The proposers, and new collaborators from Facebook and other companies, will continue to work on improving consensus over the winter by addressing remaining concerns, including doing further work to merge features from Core Coroutines into the TS approach, such as an upcoming paper “A unifying design for Executors, Sender/Receiver, coroutines, parallel algorithms and networking” by Lewis Baker of Facebook which is expected to appear in the post-meeting mailing. We expect coroutines to be proposed again for C++20 at our February meeting in Kona with this additional information, and with the national bodies having more time to absorb the large amount of new information that was presented at this meeting.
Networking: This depends on Executors, and despite some discussion about decoupling the non-Executor parts, at this meeting we decided to target merging Networking into C++ for soon post-C++20 (i.e., targeting C++23). It also might depend on Coroutines, because some experts are still working through whether there is integration work to be done to merge Networking with Coroutines.
Reflection TS v1 (David Sankel) ISO ballot continues: The Reflection TS international comment ballot was already in progress during the meeting and will conclude next month. As I mentioned in my last trip report, note again that the TS’s current template metaprogramming-based syntax is just a placeholder; the feedback being requested is on the core “guts” of the design, and the committee already knows it intends to replace the surface syntax with a simpler programming model that uses ordinary compile-time code and not <>-style metaprogramming. In San Diego, we began looking at a “next-generation” reflection proposal P1240 (Andrew Sutton, Faisal Vali, Daveed Vandevoorde).
In addition to the two Incubator Study Groups I mentioned in my pre-trip report, we also formed two new domain-specific study groups:
SG19: Machine Learning (Michael Wong). We feel we can leverage C++’s strengths in generic programming, optimization and acceleration, as well as code portability, for the specific domain of Machine Learning. The aim of SG19 is to address and improve on C++’s ability to support fast iteration, better support for array, matrix, linear algebra, in memory passing of data for computation, scaling, and graphing, as well as optimization for graph programming.
SG20: Education (JC van Winkel). We feel we have an opportunity to improve the quality of C++ education, to help software developers correctly use our language and ecosystem to write correct, maintainable, and performing software. SG20 aims to create curriculum guidelines for various levels of expertise and application domains, and to stimulate WG21 paper writers to include advise on how to teach the new feature they are proposing to add to the standard.
Thank you to Michael and JC for volunteering as chairs!
What’s next
Whew! Here is a cheat-sheet summary of our current reasonable expectations for some of the major pieces of work. Note that this is an estimate only, and progress can end up being different than expected.
And here is an updated snapshot of where we are on the schedule for C++20, which can always be found in paper P1000:
Thank you again to the approximately 180 experts who attended this meeting, and the many more who participate in standardization through their national bodies! Have a good winter… we look forward now to several interim telecons and potentially side meetings, and then our next regular WG21 meeting in February (Kona, HI, USA).